[15호]JK전자와 함께하는 ARM 완전정복 1부

JK전자와 함/께/하/는 ARM 완전 정복
Ⅰ.ARM Architecture – 1부
글 | JK전자
자료는 ARM을 처음 접하는 입문자로서 S/W 엔지니어 혹은 H/W 엔지니어를 대상으로 하였습니다. 처음에는 Cortex-M3 구조를 목표로 하였으나 전통적인 ARM(주로 ARM7, ARM9)의 구조에 대해서 먼저 이야기한 다음 Cortex-M3 구조에 대해서 하기로 마음을 고쳐 먹었습니다. Cortex-M3도 ARM 이기 때문에 전통적인 ARM의 구조에 대해서 잘 이해하고 Cortex-M3 구조와 비교해 보면서 공부 한다면 큰 도움이 될 것입니다.
ARM Architecture 강의는 특정 CPU(S3C2440, STM32Fxx) 보다는 ARM의 이론적인 구조 자체에 대해서 많은 설명을 하고 있습니다. 하지만 일반적인 ARM의 구조를 잘 이해하면 특정벤더의 CPU도 쉽게 이해할 수 있을 것이라 생각됩니다.
처음에는 주로 임베디스 시스템에 대한 이론을 공부하게 될 것이고 이후에 ARM의 구조, 레지스터, Instructions 등에 대해서 설명해나갈 것입니니다. 이론 설명이 끝나면 실제 타겟 보드를 선정하여 이론으로만 설명했던 내용을 직접 코딩해 보고 타겟에 다운로드하여 결과를 확인하는 실습을 해보도록 하겠습니다.
I. ARM Architecture ~ IV. Cortex-M3 Applications 까지 분명 쉽지 않은 지루하고도 먼 여행이 되겠지만 ARM을 공부하는 임베디드관련 엔지니어라면 언젠가는 한번은 넘어야 하는 산이라 생각됩니다. 부디 이 자료가 ARM을 정복하는데 조금이라도 도움이 되시길 바랍니다.
강의 전체 로드맵
I. ARM Architecture | 임베디드 시스템 개론에 대한 설명과 ARM7, ARM9 의 구조에 대해서 설명 합니다.
II. ARM Applications | 삼성의 S3C2440(ARM9) 개발보드(S3C2440 Mini 개발보드)를 이용해서 어셈블리어와 UART, GPIO 등을 실습합니다.
III. Cortex-M3 Architecture | Cortex-M3의 특징과 구조에 대해서 설명합니다.
IV. Cortex-M3 Applications | STM32F103VCT6 Dragon 개발보드를 이용해서 GPIO, LCD, SPI, UART, MP3, SDIO, I2C 등을 실습합니다.
이 강의 자료에 대한 모든 질의사항은 http://cafe.naver.com/avrstudio의 ARM Architecture Q&A게시판에 글을 남겨 주시거나 jk@jkelec.co.kr 로 메일을 보내주시기 바랍니다.
가급적이면 여러 사람이 질문에 대한 답변을 공유 할수 있도록 네이버 카페 게시판을 이용해 주셨으면 합니다. 감사합니다.
1.1 Embedded System 이란
ARM프로세서는 예전에는 주로 경량화된 임베디드 시스템에서 사용되었는데, 최근에는 엄청난 성능으로 무장하여 마이크로소프트사에서도 ARM을 지원하는 등 좀 더 복잡한 사용자 UI가 필요한 분야 (주로 스마트 기기)에까지 그 쓰임새가 확대되었습니다.
Embedded System의 특징을 몇가지로 요약하면 다음과 같습니다.
- 장치에 내장된 Process에 의해 특정한 목적의 기능을 수행하는 하드웨어와 소프트웨어가 조합된 경량화된 시스템
- 입출력 장치를 내장하고 있다.
- Processor 동작은 주로 S/W에 의지해 동작 한다.
- 자동차, 네트워크 장비, Mobile 단말기, 정보가전 등에 응용되고 있다.
- 저전력, 안정성, 저렴함
1.2 Embedded System 구성
임베디드 시스템은 크게 Hardware와 Software로 구성되어 집니다.
(1) Hardware
- CPU(Processor)
- Memory 장치 : ROM(NOR), RAM(SDRAM, SRAM), Storage(NAND, SD) …
- I/O 장치 : Network, LCD, GPIO …
메모리 중에서 NOR, SDRAM등은 Random access가 가능하나 NAND 메모리의 경우는 Random access가 불가능 하고 CPU 입장에서 Address를 가지고 접근할 수가 없습니다. 그래서 NAND의 경우에는 메모리라고 하기 보다는 저장장치에 가깝습니다. Address를 가지고 Random access가 가능하다면 XIP(Execute In Place)가 가능하여 부팅을 위한 메모리로서 사용이 가능합니다. 최근에는 NAND 메모리만 있어도 부팅이 가능한 디바이스들(S3C6410, S5PV210 등)이 있으나 이것은 NAND 메모리에서 직접 실행되는 것이 아니라 CPU 레벨에서 NAND 메모리의 0번 블럭의 내용을 CPU의 Internal SRAM에 로드시켜서 NAND 메모리에서 부팅이 가능한 것처럼 보여지는 것 입니다. 그래서 CPU의 OM(Operation Mode)등의 포트를 잘보면 NAND 메모리의 동작 Cycle, Size 등을 H/W 적으로 정해주는 부분이 있습니다.
(2) Software
- System Software : Firmware(OS 개념이 없음), Device Driver(OS 관점)
- RTOS, Embedded OS
- Middleware : Network Stack Protocol, File System …
- Applications
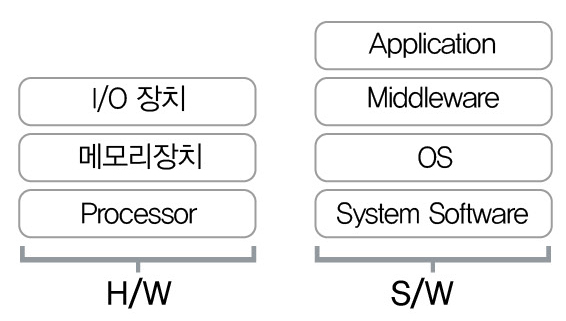
위의 그림에서 System Software는 Device Driver혹은 HAL(Hardware Abstraction Layer, 하드웨어 추상화 계층)이라고도 부릅니다.
(1) RTOS (Real-Time OS)
- 주어진 임의의 작업에 대해 정해진 시간 내에 수행할 수 있도록 하는 환경을 제공
- 개발시에 주로 운영체제와 Task들이 같이 빌드 됩니다.
- VxWorks, uC/OS, FreeRTOS, pSOS(삼성), Nucleus
RTOS에 대해서는 여러가지 정의가 많이 있지만 예를 들어보면 좀 감이 올것 같습니다. 일반적으로 우리가 사용하는 PC의 경우에 우리가 Excel 등을 실행 시켰을 경우 조금 늦게 실행이 된다고 해서 큰 일이 발생 하지는 않습니다. 실행이 될때까지 조금 기다리면 되겠죠. 하지만 무인자동차를 운행하는 시스템등에서 전방에 장애물이 나타났을 경우 반드시 부딪히기전에 멈춰서거나 피해가야 되겠지요. 어떤 상황(부딪히는 상황)에 대해서 정해진 시간(부딪히기 전)까지는 반드시 응답을 주어야 하는 시스템에서 RTOS등이 필요하게 됩니다.
(2) Embedded OS
- 여러 복잡한 작업들을 동시에 효율적으로 수행하기 위한 환경 제공
- 이미 동작 중에 있는 운영체제 상에서 새로운 프로세스를 이식 할 수 있다. –> RTOS에 비해서 Application 개발을 편리하게 할수 있습니다.
- Windows CE, Linux, Android, iOS
Embedded OS는 최근에 스마트폰, 네비게이션 등에 많이 이용되고 있습니다.
(1) CPU (Central Processing Unit)
CPU의 구성은 Processor Core + System Bus + Peripherals (H/W IP) + Memory 로 이루어 집니다. 이렇게 CPU안에 주변장치(Peripherals), Memory등을 모두 담고 있는 시스템을 SOC (System-On-Chip) 라고 한다. 아래 그림은 SOC의 한 예이다. 우리가 앞으로 공부하려고 하는 ARM도 바로 Processor Core 중의 한 종류 입니다. Data 버스와 Instruction 버스가 따로 있는 것으로 보아서 하바드 아키텍쳐 구조 입니다.
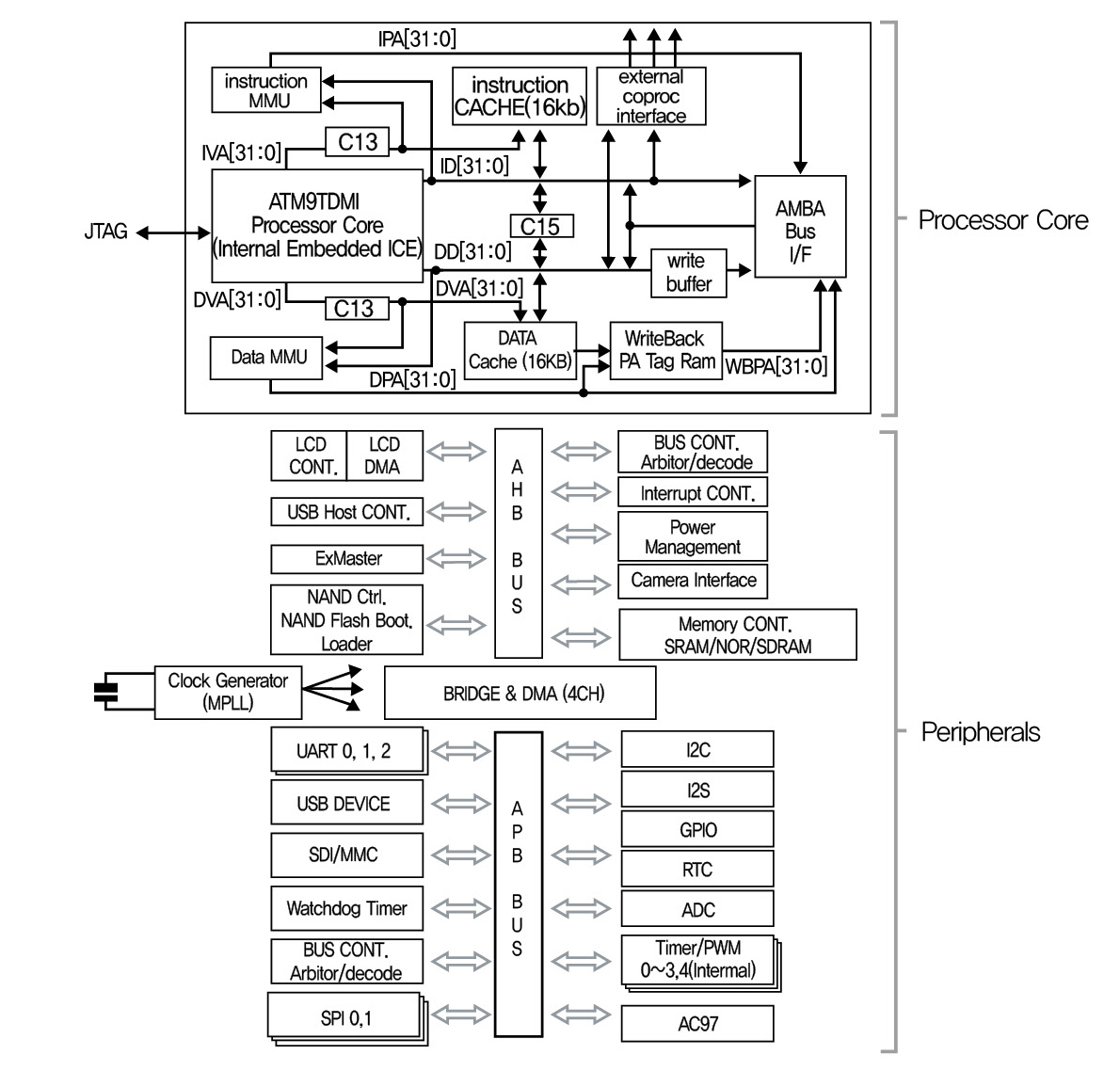
(2) Processor Core
- 메모리 장치로 부터 프로그램의 구성 요소인 명령어들을 fetch, decoding, execution 하는 동작을 합니다.
- 레지스터(Register), 연산장치(ALU), 제어장치(Control Unit), 버스(Bus), Cache memory(Optional), MMU(Optional) 등으로 구성 됩니다.
- Processor Core의 종류에는 ARM, MIPS, Intel의 Sandy Bridge 등도 Processor Core의 한 종류 입니다.
(1) RISC (Reduced Instruction Set Computer)
RISC의 대표 주자는 ARM, MIPS, SunSPARC, IBM PowerPC 등이 있습니다. ARM사의 다음 버젼에서는 64비트를 지원한다고 합니다.
- Same Length for all instruction, big code sizes
단순한 ADD명령이나 복잡한 명령이나 모두 32bit의 동일한 명령어 길이를 가지고 있기 때문에 코드의 집적도가 떨어질 수 밖에 없습니다. 이를 보완하기 위해서 16bit 코드 사이즈를 가지고 Thumb 명령어를 지원하고 있고 Cortex-M 계열에서는 ARM, Thumb명령어의 장점을 취한 Thumb2 명령어를 사용하고 있습니다.
- Simple Hardware, Low Power, Mobile Device 들을 위해서 최적화 되어 있음.
명령어의 길이가 모두 같기 때문에 코드 집적도는 떨어지지만 이 덕분에 H/W 가 단순해지고 전력 소모를 줄일수 있습니다.
- Load Store Architecture, needs many registers
명령어의 개수가 많지 않기 때문에 그에 따라서 레지스터가 좀더 필요하게 되었습니다.
(2) CISC (Complex Instruction Set Computer)
CISC 대표주자는 Intel x86, Alpha 계열이 있습니다.
- 명령어의 길이가 기능에 따라서 다르기 때문에 복잡한 H/W 처리가 요구 됩니다.
- 수행하는 명령에 따라서 명령어의 사이즈가 다르게 설계 되어 단순한 일을하는 명령어는 코드의 사이즈가 작고 복잡한 일을 수행하는 명령어는 사이크가 큽니다. 이로 인해서 코드 사이즈는 작아 졌으나 각기 다른 사이즈의 명령어를 수행하기 위한 H/W 설계가 복잡해 지고 상대적으로 RISC에 비해 전력 소모가 많아졌습니다.
- 복잡한 작업을 수행하는 다양한 명령어 들이 있기 때문에 RISC에 비해서 많은 레지스터가 필요 하지는 않습니다.
2.3 Register
프로세서 코어에 위치하고 있고 프로세서가 접근 가능한 가장 빠른 임시 기억 장치로 ARM 프로세서는 아래과 같은 3가지 종류의 레지스터가 있습니다.
(1) General Purpose Register : 프로그램 데이터 처리에 사용됩니다.
(2) Control Register : Stack Pointer, Link Register, Program Counter
- Stack Pointer는 현재 프로세스 모드의 Stack의 Top 주소를 가르키고 있습니다.
- Link Register는 서브루틴 분기시 서르부틴을 끝마치고 복귀 할 주소를 가지고 있습니다.
- Program Count는 현재 실행 중인 주소 값입니다.
(3)Program Status Register : Processor 의 상태정보와 ALU의 결과 정보를 저장하고 있습니다.
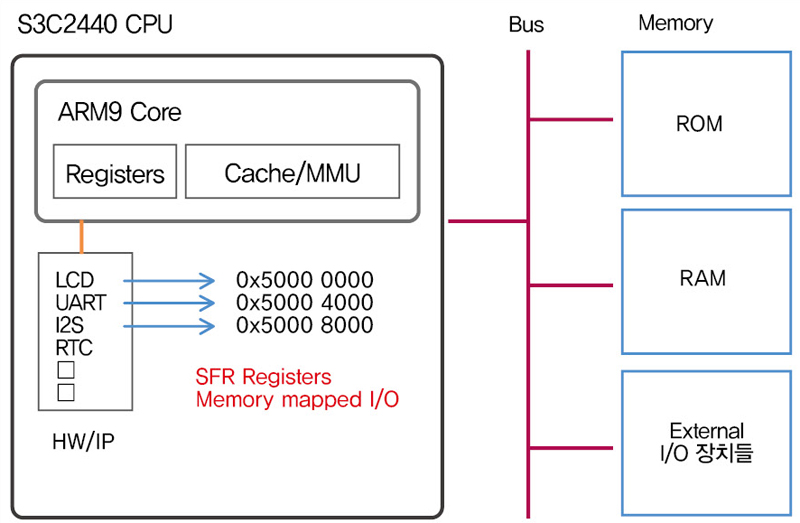
참고로 일반 레지스터 외에 특별한 레지스터가 있는데 주로 Processor 주위에 있는 주변 장치들을 제어하기 위해서 SFR (Special Function Register) 가 있습니다. 주로 Memory-Mapped 방식으로 접근이 되고 대부분 bit 단위로 제어가 됩니다.(AND, OR, EOR … ) 그리고 Memory-Mapped 되어 있다는 말은 SFR은 각 레지스터에 해당하는 주소가 정해져 있어 주소를 통해서 접근이 가능 하다는 이야기 입니다. S/W 엔지니어가 ARM 펌웨어 프로그램을 한다고 하면 대부분의 작업이 바로 SFR 레지스터를 세팅하고 제어하는 일입니다.
예제로 아래 그림은 ARM9 프로세서중의 하나인 삼성의 S3C2440의 UART제어를 위한 SFR 레지스터 입니다.

ULCON0 레지스터의 경우 0×50000000 번지를 통해서 접근이 가능합니다. 0×50000000 번지의 32Bit 레지스터는 각 비트별로 기능이 나누어져 있습니다. 0 ~ 1 비트는 UART 통신시 WordLength 를 설정할 수 있고, 레지스터별로 각 비트의 기능이 세분화 되어 있습니다.
S3C2440 CPU에서 UART 관련 SFR을 세팅하는 코드를 예를 들면 다음과 같습니다.
// S3C2440 CPU의 UART SFR 레지스터의 주소를 정의 합니다.
#define rULCON0 (*(volatile unsigned *)0×50000000) //UART 0 Line control
#define rUCON0 (*(volatile unsigned *)0×50000004) //UART 0 Control
#define rUFCON0 (*(volatile unsigned *)0×50000008) //UART 0 FIFO control
#define rUMCON0 (*(volatile unsigned *)0x5000000c) //UART 0 Modem control
#define rUTRSTAT0 (*(volatile unsigned *)0×50000010) //UART 0 Tx/Rx status
#define rUERSTAT0 (*(volatile unsigned *)0×50000014) //UART 0 Rx error status
#define rUFSTAT0 (*(volatile unsigned *)0×50000018) //UART 0 FIFO status
#define rUMSTAT0 (*(volatile unsigned *)0x5000001c) //UART 0 Modem status
#define rUBRDIV0 (*(volatile unsigned *)0×50000028) //UART 0 Baud rate divisor
// 정의된 SFR 레티스터의 주소에 직접 값을 써 넣을 수 있습니다.
rUFCON0 = 0×0; //UART channel 0 FIFO control register, FIFO disable
rUFCON1 = 0×0; //UART channel 1 FIFO control register, FIFO disable
rUFCON2 = 0×0; //UART channel 2 FIFO control register, FIFO disable
rUMCON0 = 0×0; //UART chaneel 0 MODEM control register, AFC disable
rUMCON1 = 0×0; //UART chaneel 1 MODEM control register, AFC disable
//UART0
rULCON0 = 0×3; //Line control register : Normal,No parity,1 stop,8 bits
2.4 ALU (Arithmetic Logic Unit)
(1) 산술 연산 수행 : ADD, SUB 등 연산 수행
(2) 논리 연산 수행 : AND, OR, XOR 등 연산 수행
(3) Program Status Register Update : Negative, Zero, Carry, Overflow, Saturation
Program Status Register Update 기능은 조건부 명령과 관련이 있습니다. 조건부 명령에 관해서는 ARM Instruction 에서 자세히 설명 하도록 하겠습니다.
(1) 메모리에서 명령을 인출 합니다.
(2) 인출된 명령을 분석하여 어떤 명령인지 어떤 레지스터들이 사용되는지를 확인 합니다.
(3) 명령어 실행에 필요한 제어신호를 만들어 내고 실행 합니다.
(1) CPU와 메모리 사이의 데이터 통로
(2) CPU : Bus Master, Memory : Bus Slave
(3) Bus는 Address 버스와 Data 버스가 있습니다.
2.6.1 Von-Neumann Bus
CPU와 메모리 사이에 물리적으로 하나의 버스만 존재 합니다.
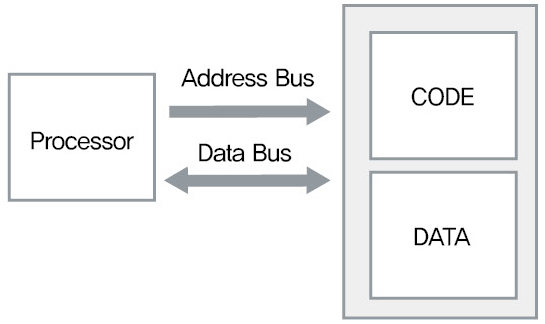
2.6.2 Harvard-Architecture Bus
CPU와 메모리 사이에 물리적으로 2개 이상의 Bus 존재하여
Von-Neumann Bus 구조에 비해서 CODE, DATA 에 동시에 접근 할 수 있습니다.

(1) 명령어 인출( Instruction Fetch )
명령어를 캐시 혹은 메모리에서 읽어 명령어 파이프 라인에 저장
(2) 명령어 해독( Instruction Decoding )
어떤 일을 하는 명령어 인지, 어떤 레지스터를 사용하는지 해독
(3) 명령어 실행( Instruction Execution )
ALU 연산수행 – 메모리 접근 명령어인 경우 메모리 접근을 위한 주소 계산
(4) 메모리 접근( Memory Access )
- ALU 연산에 의해 결정된 주소를 사용하여 메모리 접근
- 메모리 접근 명령어가 아닌경우, 결과를 한 사이클 동안 저장
(5) 레지스터 쓰기( Register Write Back )
- ALU 연산결과를 Regisger 에 기록
- 메모리에서 읽은 값을 Register 에 기록
- Cache와 더불어 프로세서의 속도를 획기적으로 개선 하였습니다.
- 하나의 명령어를 여러 개의 독립적인 작업들로 나누어 병렬적으로 실행 합니다.
ARM7의 경우 3단 파이프 라인을 가지고 있는데, 아래 4개의 명령어가 처리되는 과정을 파이프 라인이 있을 경우와 없을 경우로 나누어서 설명하도록 하겠습니다.
JOB1 : MOV R0, #0×1
JOB2 : MOV R1, #0×2
JOB3 : ADD R2, R0, R1
JOB4 : MOV R3, R2
* 파이프 라인이 없는 시스템
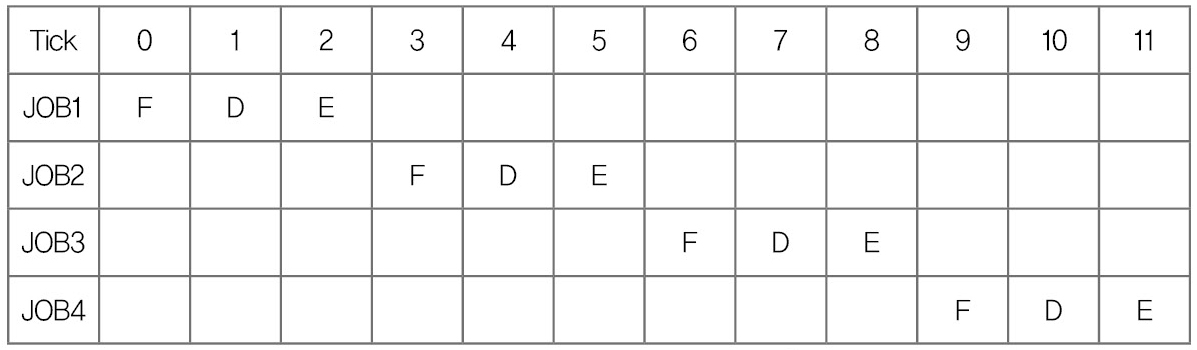
파이프 라인이 없는 시스템에서는 4개의 명령어를 수행하는 각 단계별로 3Cycle씩 총 12Cycle을 소모하고 있습니다.
* 3단 파이프 라인 시스템( ARM7 )
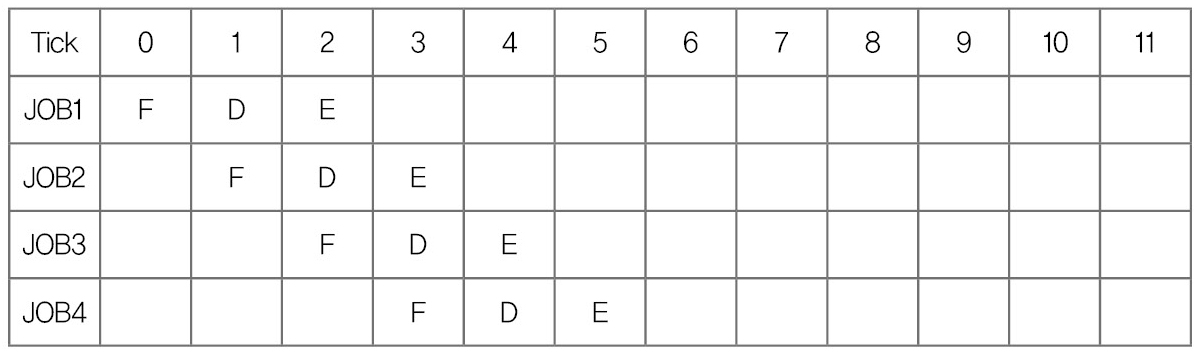
3단 파이프 라인이 있는 시스템에서는 4개의 명령어를 수행하는 처음 단계에만 3Cycle을 소모하고 다음 부터는 1Cycle이 소모되어 총 6Cycle을 소모하고 있다. 결과적으로 파이프 라인이 없는 시스템 보다 2배 정도의 성능 향상을 가져 옵니다.
- F(Instruction Fetch), D(Instruction Decoding), E(Instruction Execution)
- 위의 예는 모든 명령어가 캐시에 있어서(그러므로 모든 과정이 1Cycle 이내에 처리) 메인 메모리 접근이 없다는 가정 하에서 수행되는 결과 입니다. 만약 프로세서가 주메모리에 접근해야 하는 일이 발생한다면 추가로 메모리 접근 파이프라인 단계가 필요 하게 됩니다
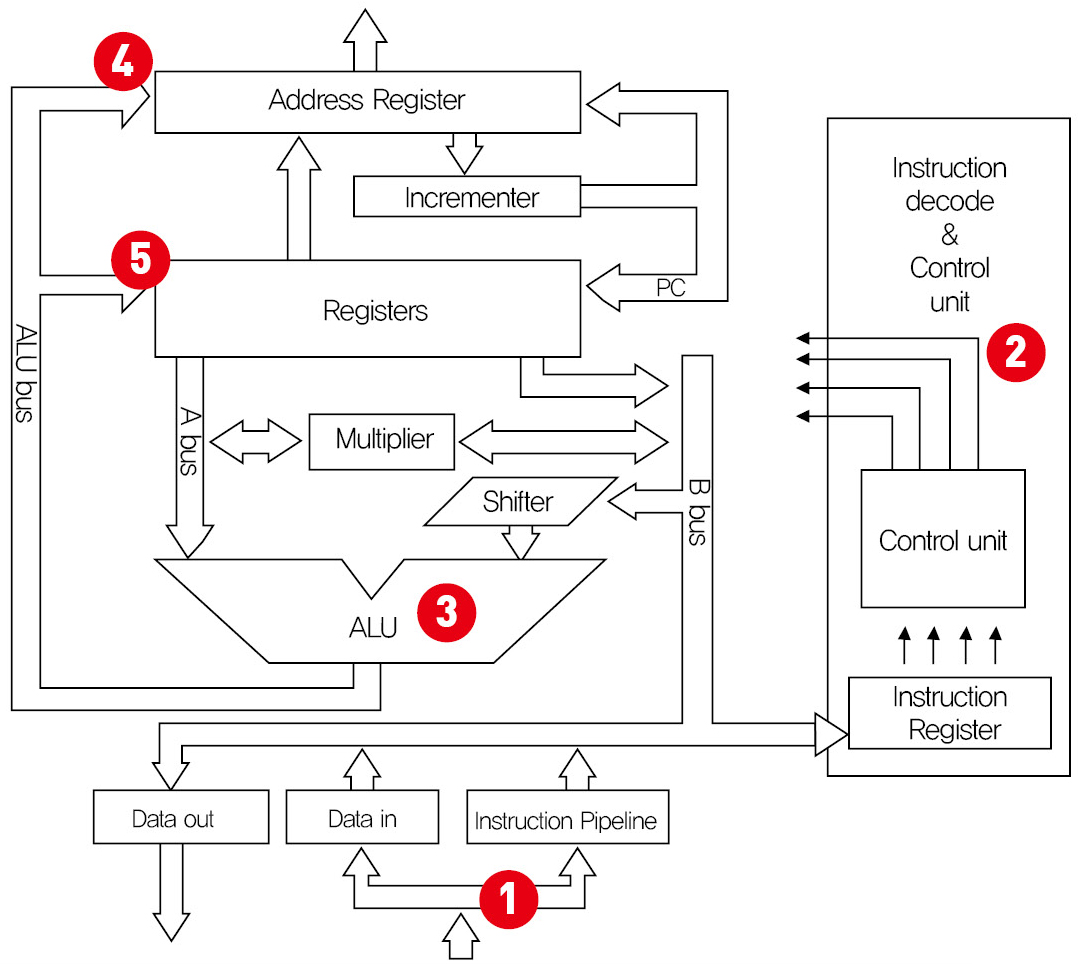
지금까지 설명한 프로세서의 기본 동작을 위의 그림(ARM7TDMI Processor Block Diagram)으로 설명을 하면, [1] 메모리에서 명령어를 Fetch하여 Instruction Pipeline에 집어 넣고 [2] 그 명령어를 Control unit 에서 해독하고 [3]ALU에서 실행, [4]메모리 접근 명령의 경우 메모리 접근할 주소 계산, [5] 그리고 결과를 다시 Register에 Write 하고 있습니다. [2] 에서 Instruction Decoder는 명령어를 읽어서 해석하는 일을 하며, 이에 대하여 Control Unit은 각종 제어 신호를 발생하게 됩니다. 예를 들어 ALU에게 더하기를 하라는 신호를 발생 시킨다던가, 또는 메모리에게 특정 주소를 Read할 수 있도록 신호를 발생시킨다든가 하는 여러 가지 Control signal들 입니다.
(1) Clock
CPU 성능을 높이는데 가장 일반적인 방법으로 단순히 CPU의 동작 클럭을 높이는 방법이 있습니다. 당연히 같은 작업을 할때 CPU Tick 시간이 빠른 CPU가 그렇지 않은 CPU보다 빠르게 동작을 하겠지요.
(2) Execution Optimization
아래 내용들은 간단히 개념 정도만 설명하도록 하겠습니다. 각 항목 하나에 대한 이론만 하더라도 분량이 상당할것 같습니다.
- Pipeline : 기본 개념은 하나의 명령어를 여러개의 독립된 작업으로 나누어 병렬적으로 실행. Pipeline은 이전에도 한번 설명 하였습니다.
- Branch prediction(분기예측) : 정상적인 프로그램 흐름에서 분기를 하게되면 Pipeline이 무너지게 되는데 이렇게 되면 다시 Pipeline에 명령어가 적재되어 실행이 되기까지 CPU는 Stall 하게 됩니다. 이를 방지하기 위해서 프로세서가 분기문을 실행하기도 전에 분기 지점을 예측하여 Pipeline을 다시 적재하는 기능 입니다. 물론 분기가 되는 지점을 프로세서에서 100% 예측할수는 없습니다. 예측이 맞으면 좋은거고(Pipeline이 무너지지 않음), 틀렸을 경우에는 원상태로 복구하는 추가 작업이 펄요 합니다. 분기 예측에는 동적예측, 정적 예측 등 여러가지 방법이 있습니다.
- Out-of-order execution
Address: Instructions
0×0004 : a = b + c
0×0008 : d = a + b
0x000c : z = x + y
위의 예제에서 보통 프로세서는 0×0004 번지부터 순차적으로 0×0008, 0x000c 번지로 실행이 되는데, 자세히 보면 0×0008번지는 “a”, “b” 와 연관이 있기 때문에 0×0004번지가 반드시 먼저 실행이 완료가 될때까지 기다린 이후에 실행이 되어야 합니다. CPU입장에서 보면 일을 하지 못하는 유휴한 시간이 되겠지요. 하지만 0x000c 번지 처럼 이전의 실행내용과 무관하다면 0×0008번지 보다 먼저 실행이 될수도 있게 하는 것입니다. 물론 소프트웨어 개발자 입장에서는 이러한 문제에 신경쓰지 않아도 시스템에서 알아서 해주죠. 이것을 S/W 개발자가 모두 생각하면서 작업을 해야 한다면 엄두가 나지 않겠죠..
- Superscalar
CPU는 한 클럭에 하나씩의 명령어를 처리하게 되어있습니다. 이를 개선해서 동시, 혹은 한 사이클 미만으로 둘 이상의 명령어를 처리하는 방식으로 슈퍼스칼라 등의 방식이 나왔으며, 이는 파이프라인을 나누어 휴지 상태의 하드웨어를 활용하도록 하는 방식을 사용합니다. 이처럼 병렬연산 구조는 겹치지 않는 명령어를 병렬로 동시 진행함으로서 프로세서의 내부에서 작동을 대기하며 휴지 상태로 있는 파트를 줄임으로서 작업효율을 높여 연산 속도를 향상시키는 것에 목적이 있습니다. 명령어 스케줄을 H/W에 의존합니다. Multi-ALU 기능으로 한 클럭에 여러 명령어 들을 fetch 해서 동시에 여러 명령어 들을 실행 시킬 수 있어 CPI(Clock per Instruction)가 1보다 작아 질수도 있음. 데이터 의존성, 자원 의존성, 프로시저 의존성이 존재하는 경우에는 동시에 실행되어서는 안됩니다. 도입한 에로는 IBM RS/6000, DEC 21064, Intel i960CA 등이 있습니다.
- VLIW (Very Long Instruction Word)
VLIW는 ILP(Instruction Level Parallelism)를 최대한 활용해서 병렬 연산을 진행하며, 이를 하나의 긴 명령어 형식 내에 동시에 실행될 수 있는 명령어(연산 코드 및 오퍼랜드)들을 여러 개 포함시킴으로써 각명령어 단위를 인출해 실행할 때 마다 여러 연산이 동시에 실행되도록 하는 방식 입니다. 명령어 코드는 길지만 하나로 취급되기 때문에 인출과 해독은 하나의 회로에 의해 이루어지고, 각 연산의 실행 사이클만 여러 개의 유니트(ALU를 비롯한 Function unit)들로 나누어져 동시에 처리되게 된다. 컴파일러단에서 명령어의 배치가 이루어 지는 방식입니다. 하나의 명령어 코드의 길이가 128, 256, 512 비트단위로 구성되어 질수 있습니다. VLIW를 도입한 예로 TI C6000 Series, ATI GPU core, Intel Itanium 등이 있습니다.
Superscalar와 VLIW가 비슷하게 생각 되어질 수 있는데, 슈퍼스칼라(superscalar)는 CPU 내에 파이프라인을 여러 개 두어 명령어를 동시에 실행하는 기술입니다. 명령어를 동시에 실행 시키기 위해서 ALU가 여러개 있어야 합니다. VLIW는 1개의 긴 명령어 안에 여러개의 명령어들을 인출하여 동시에 실행하는 기술입니다.
(3) Cache
CPU 성능을 높이는 방법으로 요즈음 디부분의 CPU들은 Cache를 사용합니다.
캐시가 생겨나게된 배경은 일반적으로 프로그램은 한번 참조했던 명령어나 데이터는 다시 참조 할 가능성이 높다는 데서 기인 합니다. 이를 참조의 지역성 이라고 합니다. 참조할 데이터가 가까운주소의 영역에 있는 특성을 공간적 지역성(Spatial locality)라 하고 최근에 참조했던 주소를 다시 참조할 가능성이 높은 특성을 시간적 지역성(Temporal locality) 이라고 합니다. 이러한 특성을 가지고 캐시의 블럭은 최근에 참조했던 주소의 데이터를 블럭단위로 SRAM 캐시 공간에 저장을 해서 CPU에서 속도가 느린 메인메모리의 접근을 최소화 하도록 합니다.
(1) Clock
2000년도 중반 이후 CPU의 클록 속도는 더 이상 급격하게 증가하고 있지 않음. 클록 속도가 증가하면 전력 소비및 누설전류 증가와 함께 심한 발열이 발생하고 이로인해 복잡한 쿨릭 시스템 설계가 필요해 집니다. 예전의 Pentium 싱글코어 CPU들의 쿨링팬을 생각하면 발열등이 어느정도 인지 짐작이 갑니다.
참고. Moore’s Law
1965년에 발표 되었고, 그 의미는 “마이크로칩의 가격은 18개월 마다 절반으로 하락” 하고
“마이크로칩의 성능은 18개월 마다 2배로 발전한다.” 는 의미이다.
2000년도 중반까지 법칙이 맞아 왔으나 최근에는 성능이 2배로 발전한다는 법칙은 한계점에 도달하고 있다.
3.3 Multi Core Processor
(1) Hyper Threading
- 하나의 CPU에서 2개 이상의 Thread를 병렬적으로 수행 시킴. 엄밀히 이야기 하면 Multi Core Process는 아닙니다.
- Hyper threaded CPU는 추가적인 레지스터들 및 하드웨어가 필요 함
(2) Multi Core
- 하나의 CPU 내부에 두 개 이상의 Processor 코어를 두어 각각의 Processor에서 프로그램을 수행 시킵니다.
- Homogeneous : 동일한, 균질의 – 똑같은 종류의 CPU를 여러개 가지고 있음
- Heterogeneous : 이종혼합(CPU+GPU) – 인텔 울트라북 등 에서 사용하는 CPU들
(3) Memory Wall
- Core 개수가 많을 수록 한 코어가 메모리를 사용할 수 있는 기회가 적어짐.
- Core의 개수가 8개 이상 증가되면, 오히려 메모리 대역폭 성능이 감소됨
(4) Parallel Programming
- Multi Core 시스템에서 성능을 높이기 위해서는 병렬 프로그래밍 효율에 달려 있음(The Free Lunch is Over)
- 인간의 보편적인 사고를 뛰어 넘어야 하는 어려움
- 컴파일러의 성능이 그다지 뛰어나지 못함
참고. The Free Lunch is Over
A fundamental turn toward concurrency in software.
예전에는 소프트웨어 개발자들이 멀티코어등을 신경쓰지 않고 개발을 해도 하드웨어 성능이 급격하게 발달이 되어 소프트웨어 성능이 개선되었으나 최근에는 무어의 법칙에도 한계점이 도달했고 마이크로 프로세서의 성능 개선의 방법으로 멀티코어쪽으로 진화하고 있어, 개발자들이 소프트웨어 성능을 개선하기 해서는 동시성등을 고려하여 개발을 해야 하지만, 이것은 쉬운 문제가 아닙니다.
- Refer to
Dr. Dobb’s Journal, 30(3), March 2005
http://www.gotw.ca/publications/concurrency-ddj.htm
[/symple_box]
4. Embedded Software
4.1 Machine & Language
(1) 기계어( Machine Code )
- Processor (CPU)가 이해하는 0과 1로 이루어진 디지털 신호
- Processor 제조사마다 코드 방식이 모두 다름
- 개발자가 기계어를 사용하여 프로그램 하는 것은 거의 불가능 : 예전에는 기계어로 직접 프로그램을 했다고 하는 분들도 계시는데 필자는 그런 정도의 세대는 아니어서 해보지는 못했지만, 생각만 해도 머리가 지끈 아파 오네요.
(2) 어셈블리어( (Assembly Code )
- 기계어 작성의 불편함을 극복하기 위해서 Processor 제조사에서 정의함.
- 처리속도가 기계어와 같음( 기계어와 1:1 로 매칭 )
- Processor Core 마다 어셈블리 코드가 다름 : ARM, MIPS, x86 명령어들 ..
- 가독성( Readability ) 이 기계어보다 훨씬 좋지만 여전히 보통이 개발자에게는 쉽지 않음
(3) C Language
- Assembly 명령어들의 단점을 극복한 언어
- 임베디스 S/W 개발에 가장 많이 이용됨
- 어셈블리보다 가독성이 매우좋고 관리가 편함
- 구조적, 모듈화 프로그래밍 가능
- 어셈블리처럼 하드웨어 직접제어 가능
(1) C언어 번역기
- C로 표현된 언어를 어셈블리로 번역하고 오브젝트 파일로 변환 시킨다.
- 사용하려는 Processor코어에 맞는 컴파일러를 사용해야 함
- C로 표현된 프로그램을 ARM코어 CPU 에서 동작시키기 위해서는 ARM 컴파일러를 사용 해야 함. 보통은 x86 PC에서 개발(코딩) 한후 ARM용 컴파일러를 이용해서 컴파일을 한후 타겟이 되는 ARM CPU 에 다운로드(퓨징) 하여 실행 시킴. x86 PC에서 사용하는 ARM용 컴파일러를 Cross Compiler 라고 함. ARM용 크로스 컴파일러로는 KEIL MDK, IAR Workbench(EWARM), ADS, RVDS, ARM용 GCC(주로 리눅스 개발환경에서 사용) 등이 있음.
(2) 오브젝트 파일
- 어셈블리 코드 섹션, 데이터 섹션
- 디버깅 정보
- 심볼 정보
4.3 어셈블러
어셈블리 언어를 기계어(오브젝트 파일)로 변환 합니다. 어셈블러와 어셈블리 언어를 혼동하면 안됩니다. 어셈블리 언어는 코드를 작성하는 언어이고, 어셈블러는 작성된 어셈블리 언어를 기계어로 변환 시키는 역할을 합니다.
4.4 Linker
- 여러 코드및 데이터 섹션들에 미리 정의된 주소를 할당합니다.
- 이미 빌드된 라이브러리들이 함께 사용 될 수 있습니다.
- 링크 작업시 같은 속성의 섹션들(.text, .ro, .rw)을 같이 묶어주는 작업도 합니다.
여기까지 컴파일러, 어셈블러, 링커등 각각이 하는 일들을 살펴 보았습니다. 그렇다면 컴파일하고, 어셈블하고, 링크작업까지 완료가 되면 생성되는 실행가능한 Binary 는 어떤 구조로 해서 만들어 지는 것일까요. 아래 그림을 통해서 알아 보도록 하겠습니다.
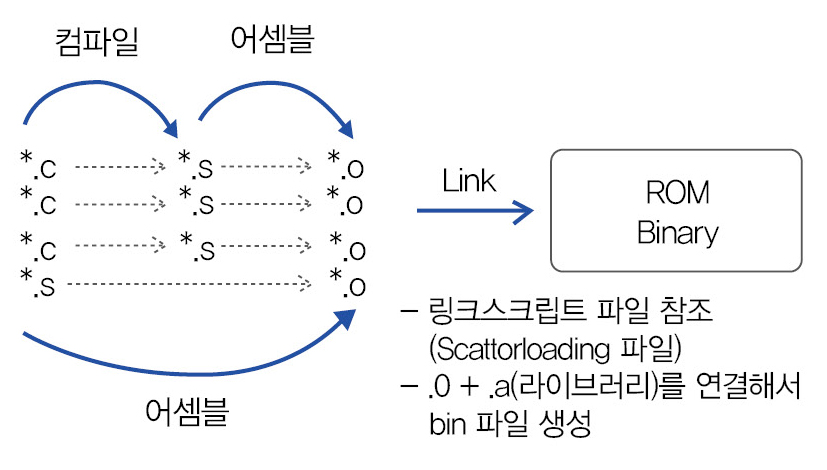
*.c 파일을 컴파일 하면 *.s 파일이 생성되고 *.s 파일을 어셈블 하면 *.o 파일이 생성이 되고 *.o 파일들과 다른 라이브러리 파일들(*.a) 을 Link 시키면 실행 가능한 bin 파일이 생성이 됩니다.
그러면 Linker는 여러개의 *.o 파일들을 어떻게 묶어서 bin 파일을 생성하는 걸까요? 이것을 알려면 *.o 파일의 구조와 링크스크립트 파일에 대해서 알아야 합니다. 링크스크립트 파일은 나중에 다시 이야기 하도록 하고 우선 *.o 파일에 대해서만 자세히 보도록 합시다.
아래 일반적이 *.c 파일이 있습니다. 각 변수들과 함수들이 메모리 상에 어떻게 자리를 잡는지 RO, RW, ZI 영역으로 구분해 보세요. 참고로 0 으로 초기화 되거나 값이 할당되지 않은 변수는 ZI(Zero-initialized) 영역, 초기값이 전역 변수는 RW(read-write) 영역, 코드나 변경 불가능한 변수는 RO(Read only) 영역으로 할당이 됩니다.
RW, ZI, RO는 GCC 등에서는 각각 .data, .bss, .constdata + .text 로 불리기도 합니다. 즉 RW = .data, ZI = .bss, RO = .constdata + .text 가 됩니다.

정답은 아래와 같습니다. 아래 오른쪽 그램에 있는 표의 내용이 바로 C코드가 컴파일 되어 오브젝트(*.O) 파일의 구성이 되는 것입니다.

여기서 중요한 사실은 함수, 전역변수, static 변수는 자기만의 주소를 가지며 Map 파일에 Symbol 형태로 나타나며, Local 변수는 자기만의 주소를 갖지 못합니다.
Symbol들이 자기만의 고유 주소를 갖고 있기 때문에 다른 파일의 함수들에서도 직접 access가 가능한 이유 이기도 합니다.
4장까지는 학교다닐때 한번씩은 들어 밨음직한 내용으로 다소 지루한 내용이었던 같습니다. 이제 5장부터 본격적으로 ARM 에 대해서 공부해 보도록 하겠습니다. ARM(영국회사) 사는 architecture core 및 system core 를 License 해주는 IP 회사 입니다. 직접 반도체를 제조하여 판매하는 것이 아니라 설계한 프로세서를 반도체 회사에 Hard Macrocell(수정불가) 또는 Synthesizable core(일부 수정 가능) 로 제공 합니다. 반도체 제조회사에서는 ARM사로 부터 제공받은 ARM core와 주변 장치를 추가하여 SOC를 만들어 사용자에게 판매하거나 자체 제품에 사용 합니다.
참고로 아래 내용들은 최근 ARM사의 연혁 입니다. Cortex-M3(2004년), M0(2009년), M4(2010년), 등을 발표한 년도 등을 알수가 있네요.
2012
- ARM, Gemalto and G&D form joint venture to deliver next-generation mobile security
- First Windows RT (Windows on ARM) devices revealed
- ARM, AMD, Imagination, MediaTek and Texas Instruments founding members of Heterogeneous System Architecture (HSA) Foundation
- ARM and TSMC work together on FinFET process technology for next-generation 64-bit ARM processors
- ARM forms first UK forum to create technology blueprint “Internet of Things” devices
- ARM named one of Britain’s Top Employers
- MIT Technology Review named ARM in its list of 50 Most Innovative Companies
2011
- ARM ranked #12 in FastCompany’s 50 Most Innovative Companies
- WIRED magazine named Warren East in the UK’s Most Influential Leaders
- ARM CEO Warren East makes Barron’s list of the World’s Top 30 CEOs
- ARM was again included in the FTSE4Good Index, designed to measure the performance of companies that meet globally-recognized corporate responsibility standards
- ARM granted Queen’s Award for Enterprise (Innovation Category)
- Microsoft unveils Windows on ARM at CES 2011
- IBM and ARM collaborate to provide comprehensive design platforms down to 14nm
- ARM and UMC extend partnership into 28nm
- Cortex-A7 processor launched
- Big.LITTLE processing announced, linking Cortex-A15 and Cortex-A7 processors
- ARMv8 architecture unveiled at TechCon
- AMP announce license and plans for first ARMv8-based processor
- ARM Mali-T658 GPU launched
- ARM expands R&D presence in Taiwan with Hsinchu Design Center
- ARM and Avnet launch Embedded Software Store (ESS)
- ARM, Cadence and TSMC tape out first 20nm Cortex-A15 multicore processor
2010
- Giesecke & Devrient secure mobile payments announcement via ARM TrustZone and G&D’s Mobicore technologies
- ARM launches Cortex-M4 processor for high performance digital signal control
- ARM together with key Partners form Linaro to speed rollout of Linux based devices
- Microsoft becomes ARM Architecture Licensee
- ARM & TSMC sign long-term agreement to achieve optimized Systems-on-Chip based on ARM processors, extending down to 20nm
- ARM extends performance range of processor offering with the Cortex-A15 MPCore processor
- ARM Mali becomes the most widely licensed embedded GPU architecture
- ARM Mali-T604 Graphics Processing Unit introduced providing industry-leading graphics performance with an energy-efficient profile
- ARM announces Corelink 400 series of AMBA 4 protocol-compliant system IP
2009
- ARM announces 2GHz capable Cortex-A9 dual core processor implementation
- ARM invests in Japanese software vendor eSOL to develop enhanced platforms for next-generation automotive electronics
- ARM launches its smallest, lowest power, most energy efficient processor, Cortex-M0
- ARM Ltd. receives Best Companies accreditation
- ARM extends its leadership in media processing by acquiring Logipard AB
2008
- ARM announces 10 billionth processor shipment
- ARM wins Britain’s Top Employer Award 2008 from crf.com
- ARM announces Industry First silicon-on-Insulator Physical IP for IBM’s 45nm SOI Foundry
- ARM Mali-200 GPU Worlds First to achieve Khronos Open GL ES 2.0 conformance at 1080p HDTV resolution
2007
- Five billionth ARM Powered processor shipped to the mobile device market
- ARM Cortex-M1 processor launched – the first ARM processor designed specifically for implementation on FPGAs
- AMBA Adaptive Verification IP launched
- RealView Profiler for Embedded Software Analysis introduced
- ARM unveils Cortex-A9 processors for scalable performance and low-power designs
- ARM Introduces SecurCore SC300 Processor For Smart Card Applications
- Warren East, CEO, wins Orange Business Leader of the Year Award
2006
- IEEE honors ARM with its 2006 Corporate Innovation Recognition award.
- ARM Cortex-A8 processor recognized as “Best In 2005″ by four leading electronics industry publications
2005
- ARM listed by Electronic Business as one of the ten most significant companies in electronics over the past 30 years
- ARM acquired Keil Software
- ARM Cortex-A8 processor announced
- ARM launched DesignStart Program
2004
- ARM acquired Artisan Components Inc.
- The ARM Cortex family of processors, based on the ARMv7 architecture, is announced. The ARM Cortex-M3 is announced in conjunction, as the first of the new family of processors
- ARM Cortex-M3 processor announced, the first of a new Cortex family of processor cores
- NEON media acceleration technology announced
- ARM technology licensed to Aplix, Atheros, Broadcom, CSR, Kawasaki, NEC, Socle, Sony Ericsson, Thomson, Toshiba, Samsung and ZRRT
- ARM acquired Axys Design Automation
- MPCore multiprocessor launched, the first integrated multiprocessor
- OptimoDE technology launched, the groundbreaking embedded signal processing core
5.1 ARM 프로세서의 종류
ARM Processor에 대해서 나름대로 정리를 해본 것입니다. 이 표와 다르게 분류를 하는 사람들도 있습니다. 이것은 제 개인적인 판단에 의한 분류 입니다.
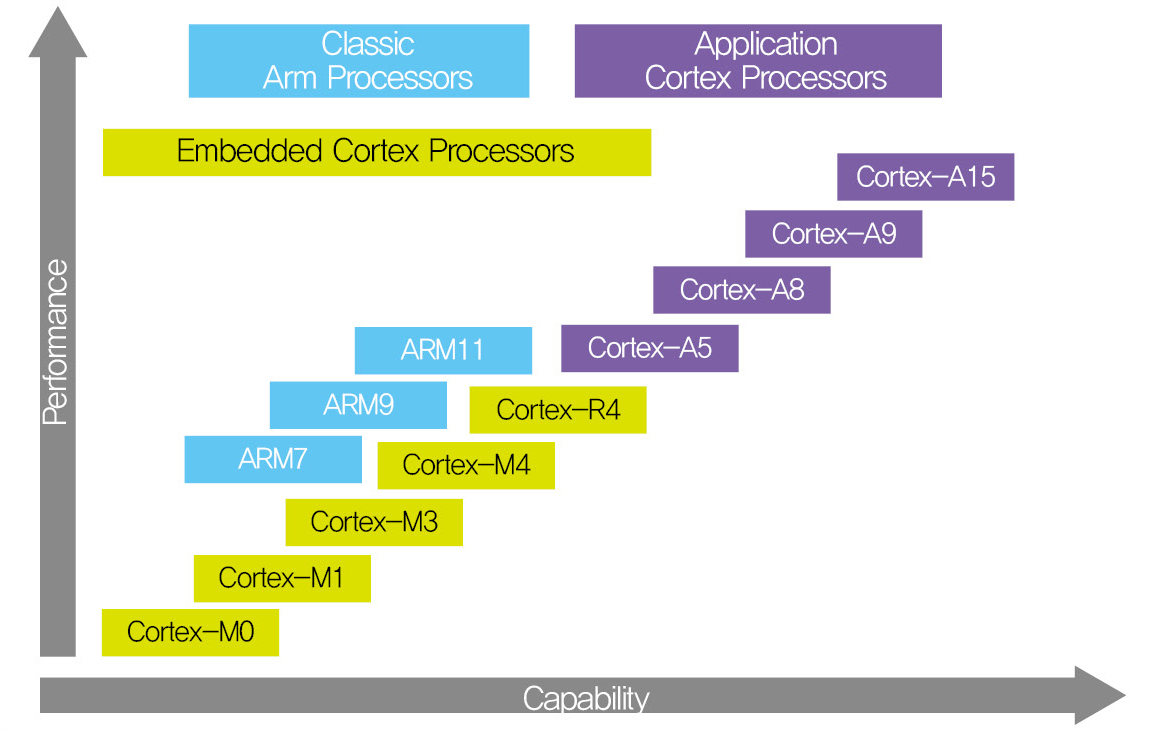
Cortex 프로세서 이전의 ARM Processors들을 전통적인 ARM으로 분류 하였고 Cortex-M, R 시리즈 까지는 기존의 uCOM시장의 프로세서들을 겨냥한 저가이면서 Realtime 프로세서 시장을 겨냥한 프로세서 이고, A 프로파일 부터는 고성능의 Application을 구현하는 프로세서로 분류 하였습니다.
5.1.1 ARM7 Processor
(1) ARM7TDMI Core
- RISC Architecture (ARM v4T)
- 3 stage pipelining
- Hard macrocell
- 32-bit ARM/16-bit Thumb Instructions
- Unified bus architecture( 폰노이만 버스 구조)
- ARM720T = ARM7TDMI + MMU + Cache(8KB Unified) + WB + AMBA
- S3C44B0 등
(2) ARM7TDMI Block Diagram

5.1.2 ARM9 Processor
(1) ARM9TDMI Core
- RISC Architecture (ARM v4T)
- 5 stage pipelining ->
Improved clock frequency
- Harvard Bus Architecture
- Simultaneous access to instruction and data memory
- Hard macrocell
- 32-bit ARM/16-bit Thumb Instructions
- ARM920T = ARM9TDMI + Dual Caches + MMUs + WB + AMBA + PA TAG RAM
- S3C2440, S3C2443 등
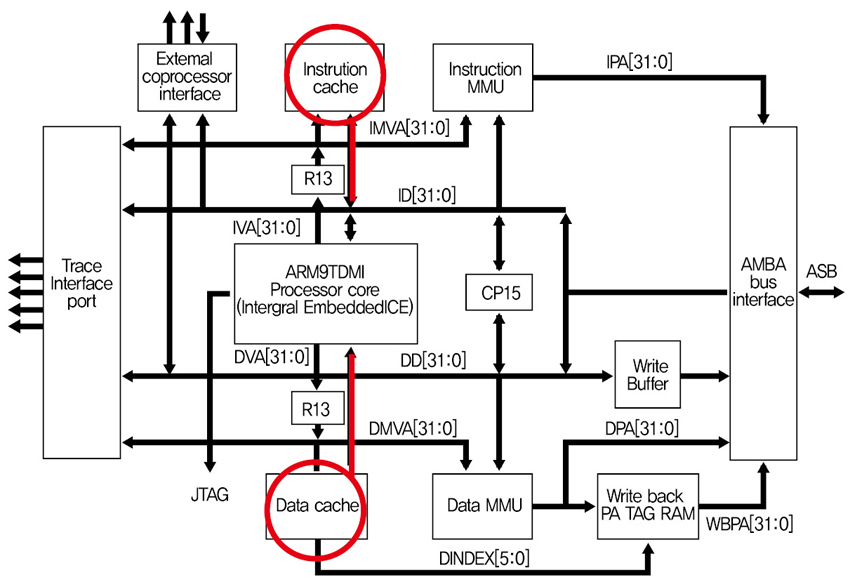
앞의 ARM7과 달리 명령어 버스와 데이터 버스가 구분이 되어 있는것을 알수 있습니다. 여기서 약간 생소한 용어가 보이는데요, Write back PA TAG RAM 이 뭘까요?
이 용어를 설명하기 위해서는 먼저 캐시 메모리의 2가지 동작 방식을 알아야 합니다. Cache메모리의 내용을 주메모리에 Write할때, Write-through 방식과 Write-back 방식이 있습니다. Write-through방식은 캐시 메모리의 내용이 업데이트 될때 주 메모리에도 동시에 업데이트가 되는 방식이고 Write-back 방식은 캐시메모리의 내용이 업데이트 되어도 바로 주 메모리에 반영이 되는 것이 아니라 Write back PA TAG RAM 에서 잠시 저장해 두었다가 블록 단위로 CPU가 쉬고 있는 동안에 주 메모리에 업데이트 하는 방식 입니다. Write Buffer는 Write-throuh 방식일 경우에 Data Cache의 내용을 주 메모리에 Write 하기 전에 Buffer 역할을 해주고, Write back PA TAG RAM은 Write-back 방식을 경우에 Data Cache의 내용을 잠시 보관하고 있다가 주 메모리에 Write를 해주는 역할을 합니다.
5.1.3 ARM11 Processor
(1) ARM1176JZ(F)-S Core
- ARM v6 Architecture
- Improved Multimedia Performance
- 2x faster MPEG4 encode/decode
- SIMD(Single Instruction, Multiple Data) Instructions : 단일 명령으로 다중 데이터를 처리하는 것을 말합니다.
- Improved Real-Time Performance
Fast Exception/Interrupt Handling
Vector Interrupt Controller -> Reduced Interrupt Latency
New Stack and Processor Mode Change Instructions
- Improved Memory Interface
Un-aligned Data Access
Mixed-Endian
8 stages pipeline
Higher clock frequency
9 stages pipeline for ARM1152T2(F)-S
Separate load-store and arithmetic pipelines
Branch prediction (static & dynamic)
Return Stack
- Other features
High Performance Integer Processor
Physically-tagged caches
Jazelle technology
VFP (Vector Floating Point)
Non Blocking
HUM (Hit Under Miss)
ARM TrustZone Technology
Thumb-2 Instruction
Intelligent Energy Manger (IEM) Technology
- S3C6400, S3C6410 ..
5.1.4 ARM Cortex Families
(1) A profile (ARMv7-A) : Application Profile
- For sophisticated, high-end applications running open and complex operating systems
- ARM, Thumb, Thumb-2 instruction sets
- S5PC100, S5PV210, OMAP3530 ..
(2)R profile (ARMv7-R) : Real-time Profile
- For real-time system
- ARM, Thumb, Thumb-2 instruction sets
(3) M profile (ARMv7-M) : Microcontroller Profile
- For cost-sensitive and microcontroller applications
- Thumb-2 instruction set only
- STM32F 시리즈
공교롭게도 새로 발표된 Cortex 패밀리의 Profile의 첫번째 이름이 A.R.M 으로 회사 이름과 동일 하네요. 우연의 일치 인가요?
5.2 ARM Processor 선택
- Embedded real-time Processor
Embedded real-time systems for storage, automotive body and powertrain,
industrial and networking applications
- Application Processor
Devices running open operating systems including Linux, Palm OS, Symbian OS and Windows CE in wireless, consumer entertainment and digital imaging applications
- Secure Processor
Smart cards, SIM cards and payment terminals
위와 같이 전문적으로 분류 할 수도 있게지만 결국 현업에서의 프로세서 선택의 가장 큰 기준은 가격대비 성능일 것입니다. 실제 구현하려고 하는 프로젝트를 구현 할 수 있는 가장 낮은 Cost의 프로세서를 선택 할 것이기 때문 입니다. 현장 에서는 Money, Money 해도 싼게 최고죠. 여기서 또 한가지 S/W 개발자의 입장에서 생각해 보면 개발의 난이도일 것입니다. 전통적인 ARM에 해당하는 ARM7, ARM9, ARM11 프로세서들은 RAM, ROM을 CPU외부에 위치 시킵니다. 이러한 이유(CPU, 제품마다 주소와 초기화 코드등이 틀려짐)때문에 코드의 호환성( 사용하는 메모리 뱅크와 메모리의 용량, 종류에 따라서 소스 레벨의 코드가 달라짐)이 매우 떨어지고 부트로더 등을 직접 작성 해야 합니다. 이에 반해서 Cortex-M, R 프로파일의 코어들은 CPU내부에 RAM, ROM을 가지고 있고 Address 또한 같은 코어를 사용하는 CPU들은 모두 동일 하게 사용됩니다. 그래서 컴파일러(개발 IDE) 수준에서 부트로더를 제공 할 수도 있습니다. 실제로 대부분의 상용 컴파일러 들은 개발자가 부트로더 코드를 작성하지 않아도 기본으로 제공하고 있습니다.
6. ARM Architecture
6.1 ARM based system
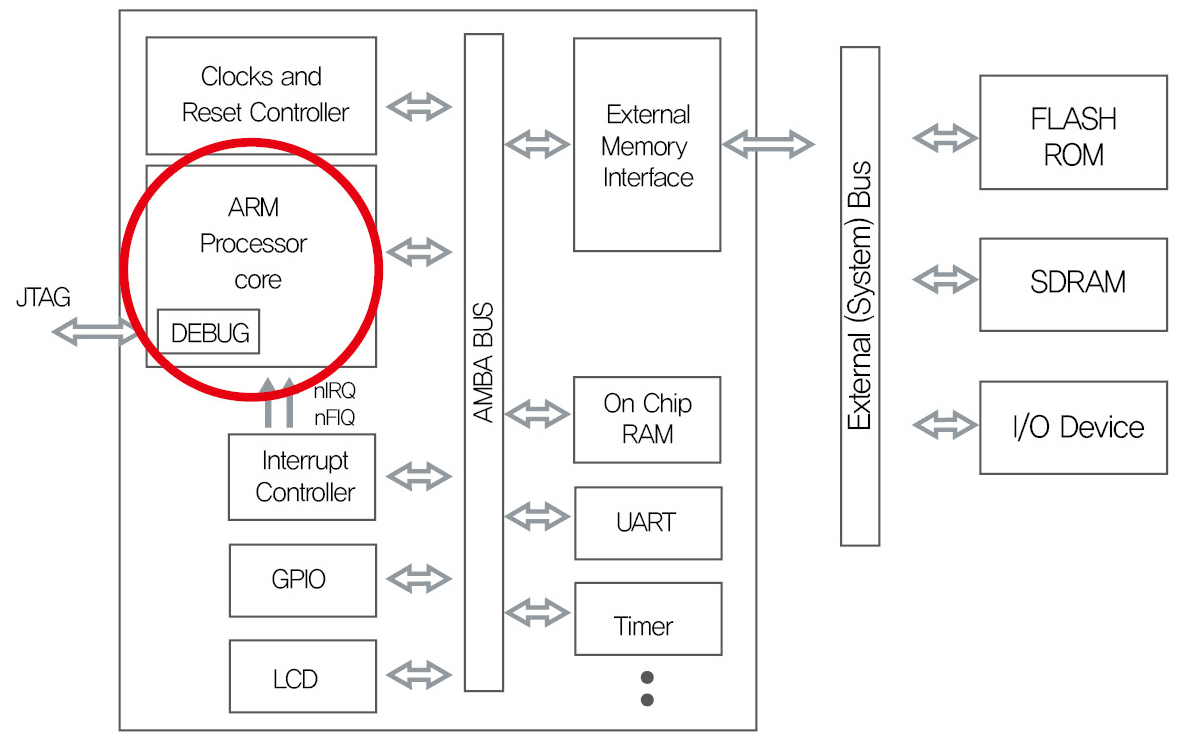
위의 블럭도는 ARM Core에 대한 블럭도는 아니고 붉은색 부분의 ARM Core를 이용해서 구현한 CPU의 한 예 입니다.
6.2 ARM Operating Modes
(1) 7개의 Processor Mode가 존재
User, FIQ, IRQ, Supervisor, Abort Mode, Undefined, System Mode
(2) Operating Mode 변경은 Hardware 및 Software로 가능 합니다.
ARM 프로세서에 전원이 인가 되면 SVC 모드에서 시작이 되고 인터럽트, 익셉션 등이 발생하면 상황에 맞추어서 H/W 적으로 Operating Mode 가 변경이 되거나 S/W 적으로는 SWI 명령어에 의해서 SVC 모드로 진입 할 수도 있습니다.
ARM Core에는 왜 이렇게 여러가지 동작 모드가 존재하는 것일까요? 아마도 아키텍쳐 차원에서 소프트웨어의 보안및 동작을 지원 하기 위해서일 것입니다. 가령 OS 설계시 커널 S/W 는 모든 권한을 가지고 수행 하도록 하고, User 어플리케이션은 제한된 권한을 가지고 수행을 하도록 설계 한다면 어플리케이션 프로세서는 모든 권한이 없는 User Mode 에서 동작 시키고 나머지 커널및 디바이스 드라이버들은 권한이 있는 나머지 모드(Supervisor, System Mode)에서 실행 시키도록 할 수 있습니다. 물론 이러한 기능은 S/W 적으로도 구현이 불가능한 것은 아니지만 구현을 위해서는 더 많은 노력이 필요할 것입니다.

- CPSR Register를 Privilege Mode 에서 S/W 로 변경 가능, User Mode에서 변경하면 Undefined Instruction Exception 이 발생 합니다.
- ARM Core에 전원이 인가되면 최초에는 Supervisor 모드로 동작을 합니다. 처음에 권한이 없는 모드로 시작을 하면 Privilege Mode로 전환 할 방법이 없겠죠.
- 각 모드는 별개의 Stack영역과 Banked Register 영역을 가지고 있습니다.
위에서 여러가지 모드가 많이 있지만 언제 어떤 모드를 반드시 써야만 하는 규칙이 있는 것은 아니고, 일반 적인 권고 사항일 뿐입니다. 대부분 OS를 운영하지 않는 단순한 펌웨어 레벨의 코드들은 초기 부팅시 설정된 Supervisor 만 사용하는 경우도 많이 있습니다. 위의 표를 보면 mode는 크게 Privileged modes와 Unprivileged mode 로 나눌 수 있습니다. 2가지 mode 구분의 차이는
(1) Privileged Mode (특권 모드)는 IRQ나 FIQ등의 Interrupt의 사용 가능 유무를 직접 설정 할 수 있습니다.
(2) Privileged Mode는 자기들끼리 서로 Mode 변경이 자유자재로 가능 합니다만, Normal Mode는 자기 스스로 Privileged Mode로 Mode의 변경이 불가능 합니다.
그것은 예를 들어, SYS ↔ FIQ, IRQ ↔ SVC과 같이 Privileged Mode → Normal Mode (USR)은 가능하지만, USR → Privileged Mode로의 변경은 불가능 합니다. 아주 중요한 사실입니다. 기억해 주세요.
결국 Privileged Mode는 자기들 멋대로 Mode에 관한 한 자유롭게 왔다 갔다 할 수 있지만, USER Mode는 가능하지 않습니다.
FIQ, IRQ, Abort, Undef 모드는 이후의 장에서 좀더 자세히 설명 하도록 하고 System mode, User mode, Supervisor (SVC) mode 에 대해서 먼저 설명 하도록 하겠습니다.
User Mode는 Application Program을 Execution 하는 Mode이고, System Mode는 Privileged Operating system task가 실행되는 mode이고, Supervisor mode는 보호된 Operating system(커널등) 에서 주로 사용되는 mode 입니다.
6.3.1 Normal Registers
앞 시간에 레지스터는 임시로 데이터를 보관하고, 연산에 사용되고, 프로그램 제어에 사용되는 접근속도가 가장빠른 임시 기억장치 라고 설명을 하였습니다.
ARM Core를 잘 이해하기 위해서는 ARM Core에 내장되어 있는 기본 Register들이 어떻게 구성되어 있고, 사용되는지를 잘 알아야 합니다. Register들은 Core가 사용할 수 있는 저장 매체 중에서 가장 빠른 속도를 자랑하며, ARM의 동작은 모두 Register들을 어떻게 사용하는냐에 따라서 동작을 제어 할 수 있습니다. 결국 ARM 프로세서를 사용 한다는 것은 아래 Register들을 가지고 연산을 하며 주 메모리와 메모리 매핑된 주변 장치들을 제어하기 위해서 Load, Store 하는 것입니다.

위의 레지스터 그림을 보면 ARM 동작모드별로 구분이 되어 있고, 동작 모드에 따라서 파란색 박스로 한번 더 구분이 되어 있는것을 볼 수 있습니다. 파란색 박스로 되어 있는 레지스터들을 뱅크드 레지스터라고 합니다. 그러니까 힌색박스의 레지스터는 동작 모드에 상관 없이 공통으로 사용되어지고 파란색 박스의 뱅크드된 레지스터는 동작 모드별로 독립적으로 사용 가능하다는 것입니다. 말로만 해서는 잘 이해가 되지 않지요.

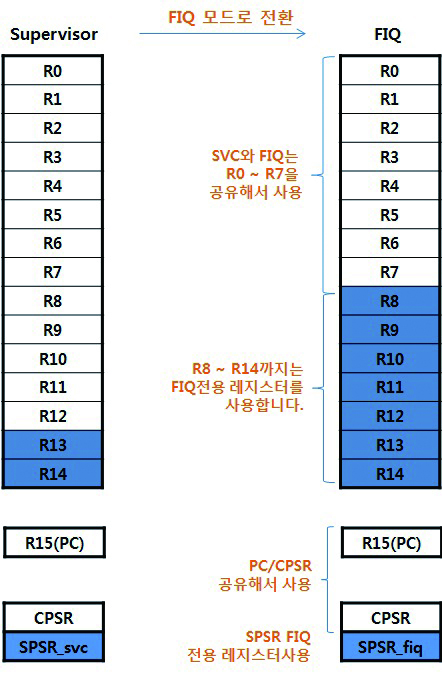
한가지 예를 들어서 설명을 하도록 하겠습니다. CPU에 최초 전원이 인가되어 SVC 모드로 동작을 하다가 FIQ인터럽트가 발생 하였을 경우 레지스터 상태는 아래와 같습니다.
FIQ로 전환이 되면 R8 ~ R14까지는 FIQ전용 레지스터가 사용이 됩니다. 이말은 FIQ모드에서 R8 ~ R14는 SVC모드에서의 R8 ~ R14와는 다른 레지스터 입니다. 즉 SVC모드에서 FIQ가 발생이 되었을때 문맥(Context) 보존을 위해서 R8 ~ R14는 저장을 하지 않아도 FIQ모드에서 R8 ~ R14는 마음대로 사용해도 됩니다. CPSR레지스터도 FIQ, SVC 모드에서 각각 존재 합니다.
여기서 문맥(Context)이라는 용어가 나오는데, 문맥이라는 의미가 무엇일까요?
S/W 입장에서 생각해 보면 프로그램이 순서대로 실행이 되다가 어떤 순간에 ISR이 발생을 하면 원래의 프로그램 실행을 잠시 중단하고 ISR 서비스 루틴으로 이동하게 됩니다. 이때 ISR서비스 루틴으로 이동을 하는것을 문맥의 전환이라고 하는데요 ISR 서비스 루틴으로 이동하고 나서 ISR서비스를 마치고 원래의 프로그램이 계속해서 실행이 되어야 하는데 만약 ISR서비스 루틴에서 특정 레지스터들(R0 ~ R12)을 사용하였다면 그 값들이 변동이 된상태에서 원래의 프로그램이 실행되던 위치로 돌아와서 계속 실행을 하게 되면 원하지 않던 결과가 나올 수 있습니다. 이런한 이유 때문에 문맥의 보존을 위해서 ISR 서비스 루틴으로 이동을 하기 전에 ISR에서 사용될 레지스터들을 스택에 임시로 저장을 하고 ISR루틴을 빠져나오기 전에 스택에 저장되어 있던 레지스터들을 다시 복원시켜 줍니다.
ISR 서비스 루틴으로 이동하는 것을 문맥의 전환이라 하고
ISR 루틴에서 사용 할 레지스터들을 임시로 스택에 저장하였다가 ISR루틴의 수행을 마치고 복귀하기전에 저장해 두었던 레지스터들을 원래의 값으로 복원하는 것을 문맥 보존 이라고 합니다.
아 ~~ 설명이 길어 지고야 말았네요. 이것도 간단하게 예를 들어서 다시 설명을 하도록 하지요.
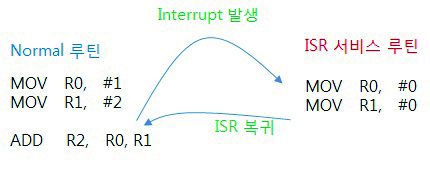
위의 그림에서 “MOV R1, #2″ 명령 이후에 Interrupt가 발생하지 않았다면 R2에서 #3이 들어가 있어야 하나 ISR 서비스 루틴에서 R0, R1을 #0으로 변경하여 ISR 루틴 복귀 후 R2에는 #0이 들어가 있습니다. 이것은 원래의 원하던 프로세스 흐름이 아닙니다.

위의 그림에서는 스택을 이용해서 ISR 서비스 루틴에서 문맥 저장(PUSH)과 복원(POP)을 하고 있어
Interrupt가 발생하여 문맥전환(Context Switch – ISR 서비스 루틴으로 이동)이 일어난 후에도
복귀 하였을때 R2에는 정상적으로 #3이 들어가 있습니다.
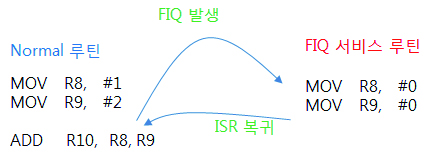
위의 예제는 FIQ 인터럽트가 발생 했을 경우이 예제 입니다. R10에 저장되는 값은 몇일까요 ?
정답은 #3이 들어가 있겠죠. 왜냐하면 FIQ 모드에서 사용되는 F8 ~ R14는 뱅크드 되어 있어서 Normal루틴에서 사용되는 R8 ~ R12와는 별개의 레지스터 이기 때문에 FIQ 모드에서 R8 ~ R12 는 문맥저장과 복원을 하지 않아도 되는것 입니다. 하지만 FIQ 모드에서도 R0 ~ R7 를 사용한다면 문맥 저장과 복원을 해야 겠지요.
이해가 가시나요. ARM 위의 3가지 경우에 대해서 직접 코드를 입력해서 테스트 해보도록 하세요. 어셈블리어로 코드를 작성 할때 아주 중요한 내용 입니다.
6.3.2 Special Registers
ARM 레지스터들중에서 R0 ~ R12 까지는 일반 연산, 임시 저장 장소등으로 사용이 되고 R13 ~ R15까지는 조금 특별한 의미를 가지고 있습니다. 그리고 CPSR(Current Program Status Register) 이라는 상태 레지스터도 있습니다.
(1) R13
- Stack Pointer(SP)
- ARM 동작 모드별로 스택 포인터를 가르키고 있습니다.
- R13(SP)는 ARM 동작 모드별로 뱅크드 되어 있는 레지스터 입니다.
(2) R14
- Link Register(LR)
- 함수 호출시 리턴될 주소를 가지고 있음
- R14(LR)는 ARM 동작 모드별로 뱅크드 되어 있는 레지스터 입니다.
함수 호출시 복귀할 주소를 저장하기 위해서 레지스터 까지 1개를 할당했는데 어떤 장점이 있을까요 ?
여러번 분기(BL)하는 경우가 아닌 한번만 분기(BL) 하는 경우라면, 함수 에서 원래의 주소로 복귀할때 스택을 사용하지 않고 R14 레지스터를 사용함으로써, 그 속도에서 이익을 얻게 되는 것입니다.
* 스택 접근 = 메인 메모리 접근 = 느림
레지스터는 CPU가 접근 할 수 있는 가장 빠른 고속의 메모리 저장 공간 이라고 생각하면 되겠습니다.
(3) R15
- Program Counter(PC)
- PC를 사용하여 메모리에서 명령어를 Fetch
- R15(PC)는 프로세서 모드에 상관없이 하나의 R15를 가지고 있음( ARM 동작모드별로 뱅크드 되어 있지 않습니다.)
(4) CPSR
- Program Status Register (CPSR)
- CPSR은 ARM 동작 모드별로 뱅크드 되어 있는 레지스터 입니다.
- 프로세서 모드가 변경이 되면 하드웨어적으로 변경되기 이전의 CPSR 복사본이 SPSR( Saved Program Status Register – CPSR의 뱅크드 레지스터) 에 저장이 됩니다.
- User, System 모드를 제외하고 각 동작 모드마다 하나씩 존재 합니다.
아래 그림이 좀 복잡해 보이기는 하지만 CPSR도 32bit 레지스터일 뿐입니다. 지금부터 하나씩 파혜쳐 보도록 하지요.
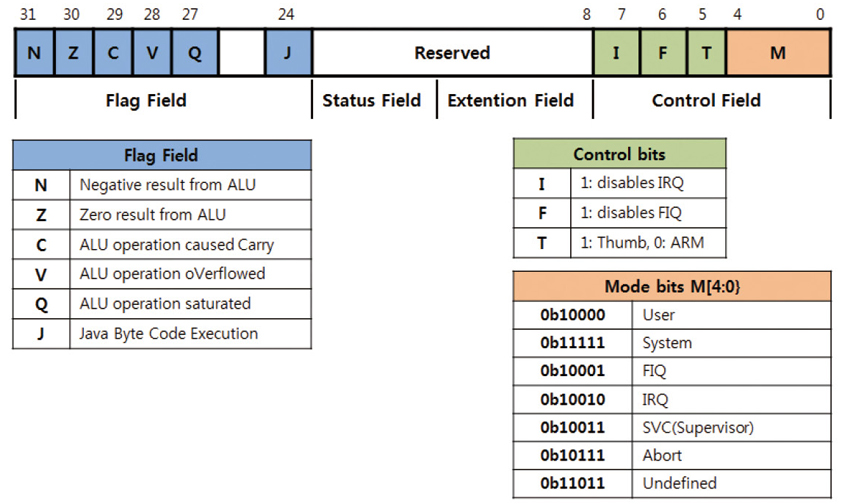
앞에 NZCVQ는 Flag field라고 해서, 뭔가 연산한 후에 set되는 register입니다. 이 field는 방금 처리된 ALU의 연산 결과의 상태를 나타냅니다.
1) N : Negative – 연산결과가 마이너스인 경우에 set 됩니다.
2) Z : Zero – 연산결과가 0인 경우에 set 되요.
3) C : Carry – 연산결과에 자리 올림이 발생한 경우에 set 됩니다.
4) V : oVerflow : 연산의 결과가 overflow 났을 경우에 set되는데, Over flow라는건 넘치는 경우니까 원래 가져야 하는 Range보다 결과 값이 큰 경우가 그 경우에 해당됩니다.
이것의 필요성은 ARM의 철학이기도 한데, ARM core는 Opcode를 Memory에서 가져오자 마자 (Fetch) 이를 무조건 실행하는 것이 아니라 Condition flag인 NZCV를 보고 바로 앞 opcode의 실행결과를 보고 실행할지 말지를 결정할 수 있습니다.
Default는 AL “Always” , condition과 관계없이 항상 실행 하는 것입니다. Control Field에 대해서는 우선 여기까지 설명을 하고, ARM Instruction에서 좀더 자세히 예를 들어서 설명을 하도록 하겠습니다.
Control Field의 7번 비트인 “I” 을 1로 마스킹을 하면 인터럽트가 발생 하지 않습니다. 인터럽트를 받아 들이기 위해서는 0으로 Clear 해야 합니다.
마찬가지로 Control Field의 6번 비트인 “F” 을 1로 마스킹을 하면 Fast 인터럽트가 발행 하지 않습니다. Fast 인터럽트를 받아 들이기 위해서는 0으로 Clear 해야 합니다. 마지막으로 5번 비트인 “T” 모드가 있습니다. ARM Core는 초기 부팅시에는 무조건 ARM 모드(5번 비트의 “T” 가 0으로 설정 됨)에서 시작이 되고 경우에 따라서 Thumb mode로 전환을 할 수가 있습니다. Thumb mode에 대해서는 이후의 장에서 다시 설명을 하도록 하겠습니다. 앞절에서 ARM에는 7가지의 동작 모드가 있다고 하였는데, 이 동작 모드들에 따라서 위의 표와 이 CPSR의 하위 5bit(Mode bits)의 값들이 설정이 됩니다.
Exception 이란 무엇일 까요? 사전적인 의미로는 “예외” 라고 되어 있습니다. 하지만 우리는 지금 ARM을 공부하고 있기 때문에 좀더 ARM 적인 표현을 한다면, 외부 요청이나 프로그램 오류로 인해 코드의 정상적인 흐름을 벗어나는 동작 이라고 설명을 하겠습니다. 코드의 정상적인 흐름을 벗어난다는 이갸기는 PC(R15)의 주소가 바뀌게 되는 것입니다. 아래 그림은 Exception 중에서 IRQ 예외 상황이 발생했을 경우에 Exception 처리 흐름의 기본적인 예제 입니다.
PC의 0×1004를 실행하고 나서 IRQ 예외 상황이 발행을 하게 되면 코드의 정상적인 흐름을 잠시 중단하고 IRQ 예외상항을 처리해 주어야 합니다. 여기서 IRQ예외 상황을 처리해 주는 루틴을 Exception Handler하고 합니다. Exception Handler 에서는 7가지 예외 상황(여기 예에서는 IRQ 예외)에 맞는 적절한 처리를 하고 Exception이 발생하기 이전으로 복귀하면 됩니다. Exception Handler에서 한가지 주의 할 사항은 Exception이 발생하기 이전으로 복귀하기 전에 반드시 문맥을 복원하고 복귀 해야 합니다.
그리고 위의 그림에서는 편의상 IRQ 예외 처리를 위해서 0×3000번지로 코드의 흐름이 변경되었지만 실제로 ARM에서는 IRQ 가 발생하면 코드의 흐름이(PC) 0×00000018 로 H/W 적으로 변경이 되고 0×00000018 에서는 다시 실제로 예외 사항을 처리하는 Exception Handler 함수로 분기하는 방식으로 처리가 됩니다.
0×00000018 번지를 Exception Vector라고 하고
ARM에서는 7가지의 Excepton이 존재하는데 이러한 예외 상황이 발행을 하면 각 예외 상황에 따라서 미리 할당된 주소에 있는 ARM 명령어가 수행이 됩니다.
아래 표는 ARM에서의 7가지의 Excepton 에 대하여 주소와 각 Exception에 할당된 정해진 Vector 주소 입니다.
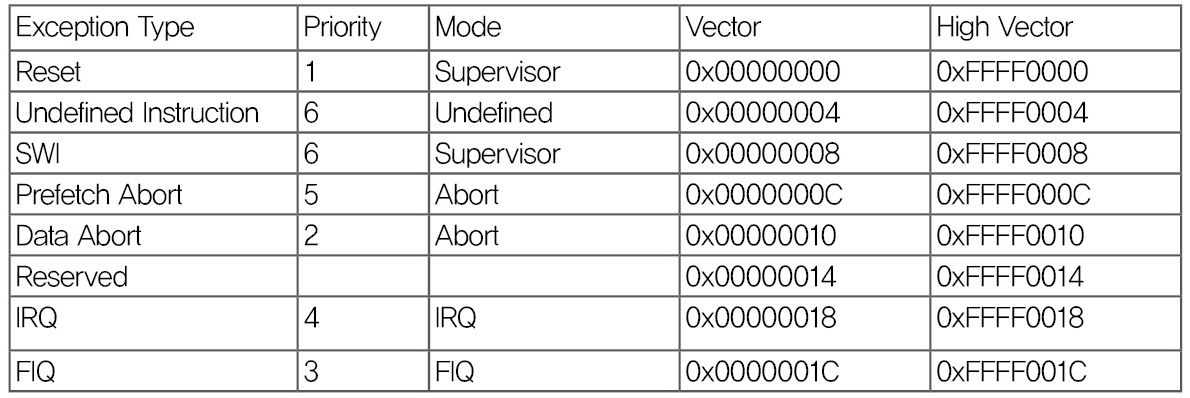
Exception의 종류와 앞에서 배웠던 ARM 동작 모드와의 관계를 혼동해서는 안됩니다. 예외 상황이 발생하면 그에 따라서 H/W 적으로 ARM 동작 모드가 변경이 되는 것입니다. Priority는 같은 시간에 다수의 예외 상황이 발행하게 되면 우선순위가 높은 놈이 먼저 발생을 하겠지요.
보통 Vector주소는 0×00 번지에서 32bit(4Byte)단위로 증가 하는데, High Vecotr로 설정이 되면 시작 주소가 0xFFFF0000가 됩니다. Windows CE에서는 High Vector를 사용한다고 합니다.
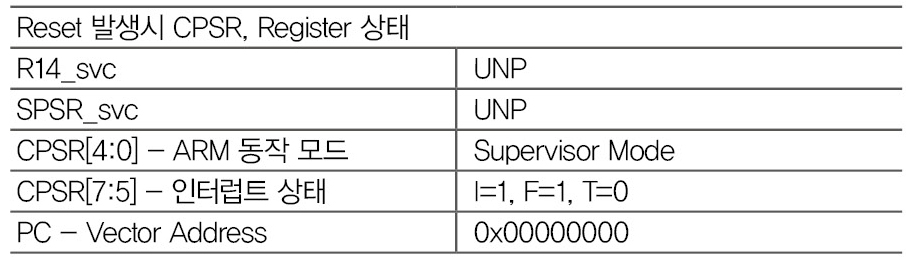
(1) Reset
ARM Core에 전원을 인가하는 등에서 발행
(2) Undefined Instruction
ARM Processor 에서 정의되지 않은 명령어 등을 실행 하는 경우에 발생

Return 이라고 되어 있는 항목은 Exception Handler 수행을 마치고 원래의 프로그램 흐름으로 복귀할때, R14에 H/W적으로 들어가는 복귀 주소에 따라서 달라지게 됩니다. 각 Exception 종류에 따라서 R14에 들어가는 복귀 주소가 달라 지므로 주의 해야 합니다.
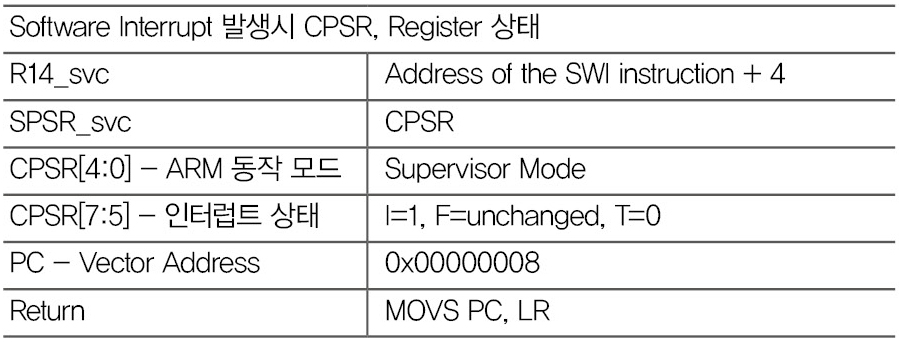
(3) Software Interrupt
비 특권모드에서 특권 모드로 진입하기 위해서 Software Interrupt 명령어를 실행한 경우 발생
(4) Prefetch Abort
Illegal 주소에서 명령어를 가져와서 실행 하려는 경우에 발생

(5) Data Abort
Illegal 주소에 Data를 쓰거나 읽기 동작을 시도하는 경우에 발생

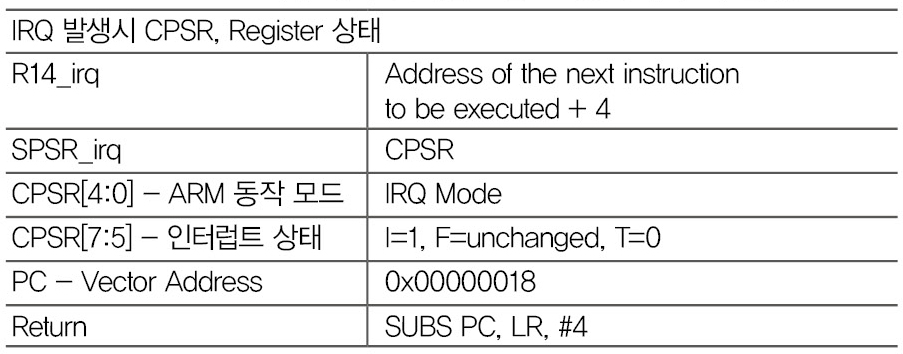
(6) IRQ
ARM Processor 외부에서 인터럽트를 요청한 경우에 발생
(7) FIQ
ARM Processor 왼부에서 Fast 인터럽트를 요청한 경우에 발생

Exception Handler를 종료하고 원래의 프로세스 흐름으로 복귀하는 Return 명령어의 공통점은 SUBS, MOVS 등으로 끝에 “S” 접미사가 따라 붙습니다. “S” 접미사의 의미는 Destination 레지스터가 만약 PC(R15) 라면 SPSR을 CPSR로 복원 하라는 의미의 접미사 입니다. 물론 이러한 과정은 H/W 적으로 이루어 집니다.
아래 그림은 IRQ 발생시 처리하는 절차 입니다. 위에서 언급했던 내용들과 비교해 보시기 바랍니다.
프로그램의 정상적인 흐름에서 0×1004번지 명령어 처리중에 IRQ 예외가 발생하면 0×1004 번지의 명령어 수행이 완료가 된 이후에 IRQ 예외의 Exception Vector인 0×0018번지로 PC가 이동을 하고 0×0018번지에서 실제로 IRQ 예외처리 핸들러 함수가 있는 번지로 다시 이동을 한다음 예외처리를 완료하고 다시 IRQ 예외가 발생한 다음 번지의 명령어가 있는 곳으로 “SUBS PC, LR, #4″ 에 의해서 복귀해서 IRQ 예외가 발생하지 않은것처럼 계속해서 Normal 루틴이 실행이 됩니다.

위에서 한가지 설명을 빠뜨린 것이 있는데, IRQ 예외가 일어나면 H/W 적으로는 다음과 같은 일이 발생을 합니다.
(1) CPSR 백업 : SPSR_irq = CPSR_svc
(2) ARM 모드로 전환( 예외상황에서는 항상 ARM 모드로 수행이 됨) : CPSR.T = 0
(3) CPSR MODE 를 IRQ 모드로 변경 : CPSR[4:0] = 0b10010
(4) IRQ 모드 마스킹(인터럽트가 Disable 됨) : CPSR.I = 1
(5) R14_irq = PC + #8
(6) PC = 0×18( IRQ Vector address)
(5)번 항목에서 LR(R14)에 PC + #8이 들어가는 이유는 특정 번지의 명령어가 수행될때 IRQ가 발생을 하면 Execution – Fetch – Decode 의 Pipe line 에서 보면 Execution 단계에서 실제 PC는 현재 실행중인 명령어의 Fetch(+4), Decode(+8) 단계가 실행이 되고 있기때문에 LR에는 PC + #8 번지의 값이 들어 가게 됩니다. 하지만 IAR, KEIL, ADS 등의 컴파일러 등에서는 IRQ발생시 LR레지스터 값을 조사해보면 LR의 값이 PC + #8 가 아니고 LR = PC 의 값과 동일하다고 표시 됩니다. 이것은 컴파일러 사용자의 혼동을 피하기 위해서 이렇게 표시를 하고 있는것 같습니다.
Exception과 Interrupt는 무엇이 다를까요. 경우에 따라서는 비슷한 의미 일수도 있습니다. 하지만 몇가지 다른점이 있습니다.
(1) Exception
- 특정 명령어 실행에 의한 오류시 발생
- 클록에 동기 적으로 발생됨 : Exception은 주로 Core내부에서 발생하기 때문에 Core의 클럭에 동기적으로 발생을 합니다.
- 메모리 접근 오류, 디버깅 중단점, divide by zero… 등
- 넓게 생각하면 Exception은 IRQ를 포함한다고 생각해도 됩니다.
(2) Interrupt
- Processor 의 명령어 실행과 관계없이 Processor 외부에서 주로 발생 –> 클록에 비동기 적으로 발생 할수도 있음
ARM Cortex시리즈 이전의 전통적인 ARM Core에는 인터럽트로 받아 드릴 수 있는 방식은 IRQ, FIQ 2가지 밖에 없습니다.

위의 그림은 ARM9 Core의 인터럽트 블럭도 입니다. Interrupt Controller 와 Physical Interrupts 소스는 ARM Core 내부의 블럭이 아닙니다. Interrupt Controller 와 Physical Interrupts 부분은 ARM Core를 이용해서 설계한 S3C2440등의 CPU 블럭 입니다. 다시한번 말씀드리지만 ARM Core에는 IRQ나 FIQ냐만을 받아 들일 수 있습니다. Interrupt Controller는 CPU Vendor에 의해서 다르게 디자인 될수도 있습니다.


