[65호]스마트 차선 변경 시스템


2020 ICT 융합 프로젝트 공모전 장려상
스마트 차선 변경 시스템
글 | 영남대학교 양성은, 박유나, 지준영
1. 심사평
칩센 지원자께서는 ‘ADAS(Advanced Driver-Assistance Systems)’ 라는 용어나 시스템을 들어보셨을 수도 있을듯합니다. 최근 많은 차량에 운전, 주차, 안전을 위한 여러 가지 시스템이 적용되고 있고, 그 중 지원자가 구현하고자 한 작품은 ADAS 기능 중 BCW 기능에 해당할 것으로 보입니다. 보고서에도 작성되어 있듯이 실제로는 고려하기 힘든 많은 변수들이 있고 그러한 부분을 이미 진행된 기술의 학습을 통해서 개선이 가능할 것으로 보입니다. 시연 영상에서 실제 도로와 유사한 이미지로 화면이 보이는 것이 매우 흥미로웠습니다.
펌테크 현재 상용화되어 널리 사용되는 기술이지만 학생의 눈높이에 맞추어 전체적으로 꼼꼼하게 잘 기획되었고, 간결하게 잘 구성한 작품이라고 생각합니다. 제품 완성도 면에서 우수한 작품이라고 판단됩니다.
위드로봇 차량의 BSD 기능을 구현한 작품입니다. 카메라 캘리브레이션을 통해 초음파 센서 거리 값과 융합을 하면 더 좋은 결과를 얻을 수 있습니다.
2. 작품 개요
2.1. 구현 배경
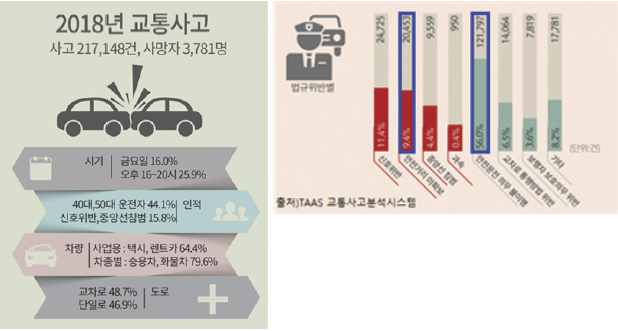
TAAS 교통사고분석시스템에 따르면, 2018년 교통사고는 21만 건이 넘는 사고와 3,781명의 사망자가 발생했으며 교통사고로 수년간 인명피해가 많이 발생하고 있다. 이러한 교통사고가 일어나는 경우는 신호 위반, 안전거리 미확보, 중앙선 침범, 과속, 안전운전 의무 불이행, 교차로 통행방법 위반, 보행자 보호의무 위반 등 여러 가지가 있다.
여기서 도로교통공단에서 제시한 안전운전(안전한 도로이용)수칙에는 안전거리 유지, 좌석 안전벨트의 착용, 진로 변경 등을 다루고 있다. 안전거리 유지 관련 기술은 고속도로 주행보조(HDA)로 고속도로와 자동차 전용도로 주행 시 앞차와의 거리를 유지하며 운전자가 설정한 속도로 곡선로에서도 차선을 유지하며 주행하도록 돕는 기술이 있다. 자동차 안전벨트 미착용 알림장치 뿐만 아니라 후진 주차/출차 시 후방 장애물 인식 및 제동을 돕는 후방 주차 충돌방지 보조(PCA)등을 탑재해 안전 편의성을 극대화하였다.
따라서 우리가 구현하고자 하는 기술은 차선 변경에 대한 교통사고를 일으키는 원인의 시발점을 봉쇄하는 동시에 이와 같은 스마트한 시대에 걸 맞는 기술을 접목 시킬 기술을 구현하는 것이다.
2.2. 스마트 차선 변경 시스템이란?
스마트 차선 변경 시스템은 운전자가 방향지시등을 키게 되면 변경하고자하는 차선의 운전자 차량 기준에서 가장 가까운 차량과의 거리를 실시간으로 측정하여 운전자의 차량 내 모니터를 이용해 시각적인 정보를 제공함으로써, 운전자가 보다 안전하고 편리하게 차선변경을 할 수 있도록 도움을 주는 시스템이다.
초음파 센서를 통해 거리를 측정하여 차선 변경 시 운전자에게 위험(빨강색) – 주의(주황색) – 안전(초록색) 세 단계로 나누어 시각화 함으로서 위험을 좀 더 쉽게 감지할 수 있게 돕는다.
2.3. 대상 및 기대효과
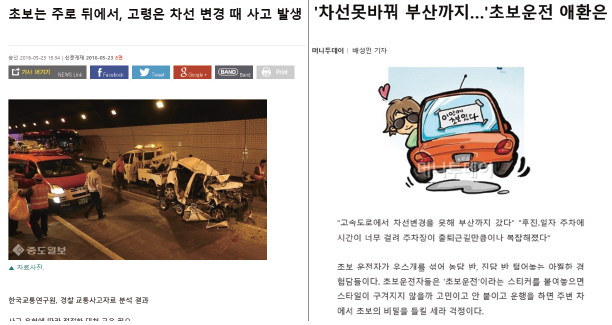
한국 교통 연구원, 경찰 교통사고자료 분석 결과에 따르면 차선을 변경 시 충돌사고를 많이 내는 것으로 나타났다. 그리고 차선 변경을 하지 못해 부산까지 갔다는 기사를 접할 수 있다. 이와 같이 해당 기술의 초점 대상은 운전에 미숙한 사람으로 해당 기술은 차선 변경에 대한 부담감을 줄이고 안전편의성을 극대화하는 역할을 한다.

또 운전에 미숙한 사람뿐만 아니라 모든 운전자를 대상으로 확장 할 수 있다. 도로를 나가보면 상당히 많은 운전자들이 차선 변경 시 방향지시등을 켜지 않은 모습을 볼 수 있는데, 이유를 물어보면 대다수가 “귀찮아서”라는 대답을 한다. 운전자들이 대수롭지 않게 생각하여 잘 사용하지 않는 기능을 개선하여 보다 안전하게 운전할 수 있다는 장점을 살려 방향지시등을 사용하게끔 유도하는 효과도 기대해본다.
끝으로 차선 변경 시 일어나는 교통문제를 개선해 조금이라도 더 많은 운전자가 편리하고 안전한 도로 주행을 하길 바라는 기대를 해본다.
3. 작품 설명
3.1. 주요 동작 및 특징
3.1.1. 카메라 동작 및 특징

회로[첨부 1]에 연결된 스위치가 ON 일 때, 차선 변경 알고리즘이 실행되면서 카메라(Logitech사의 960-001063 – Webcam, HD Pro, 1280 x 720p Resolution, 3MP, Built In Microphone, [첨부 2])가 동작하게 된다.
3.1.2. 초음파 동작 및 특징

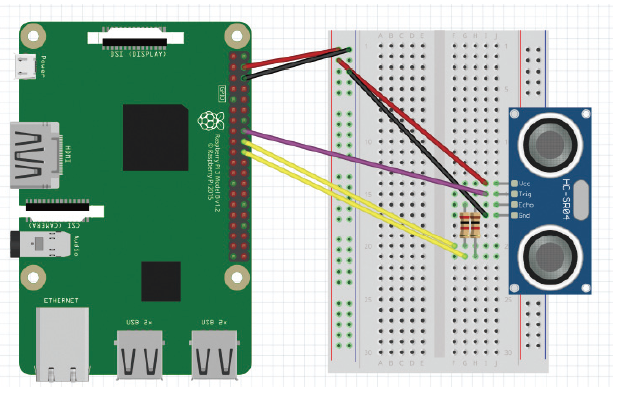
회로[첨부 5]에 연결된 스위치가 ON 일 때, 같이 연결되어 있던 초음파(HC-SR04, [첨부 6])가 동작하게 된다. HC-SR04 초음파 센서는 4가지 핀이 있으며, 순서대로 VCC핀, Trig핀, Echo핀, GND 핀을 가지고 있다.
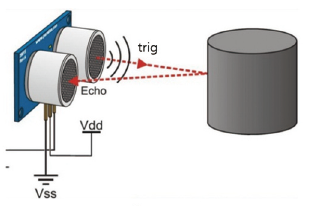
여기서 초음파 센서의 동작을 살펴보면, Trig핀에 High signal이 들어오면 초음파를 전송하고 전송된 초음파가 사물에 반사되어 돌아오면 High signal에서 Low signal로 바뀐다. High상태에서 Low상태로 바뀐 시간을 이용하여 거리를 측정할 수 있다. 거리 계산 공식은 “거리 = 시간 x 초음파의 속력”이며, 초음파의 속력은 공기 중에서 340m/s로 이동하기에 식에 340m/s를 대입하여 계산하면 된다. 참고로 시간은 왕복시간으로 측정이 되기 때문에 2를 나누어 주며, 마무리로 단위까지 맞춰주어 간단하게 거리를 구할 수 있다.

이러한 초음파를 활용하여 [첨부 8]운전자 차량의 뒷면에서 대각선 양쪽 끝에 초음파 센서를 장착한다는 가정에 하에 초음파 센서는 운전자 차량과 변경하고자 하는 차선의 뒷 차량과의 거리를 측정할 수 있게 된다. 더 나아가 초음파 센서가 측정한 거리를 라즈베리에서 받아 처리함으로써 차선 변경 시 안전 정도를 운전자가 보는 모니터에 영상처리를 통해 간단하게 인지할 수 있게 해주는 역할을 제공한다. [첨부9]같은 경우 위험(빨강색) – 주의(주황색) – 안전(초록색) 중 주의 단계로 주황색으로 위험 정도를 표시하고 있는 것을 볼 수 있다.
3.1.3. 차선 변경 동작 및 특징
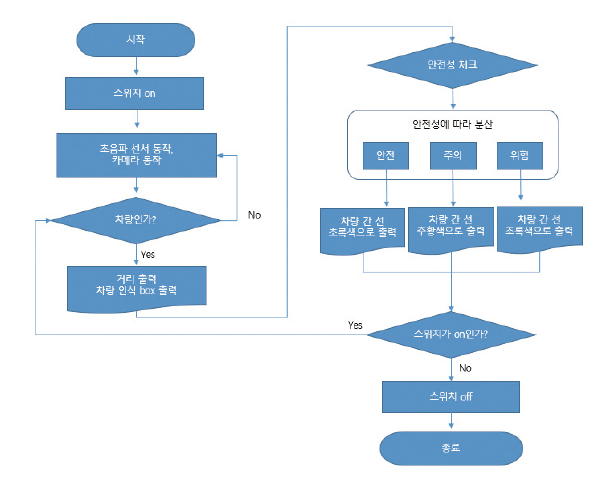
3.2. 전체 시스템 구성
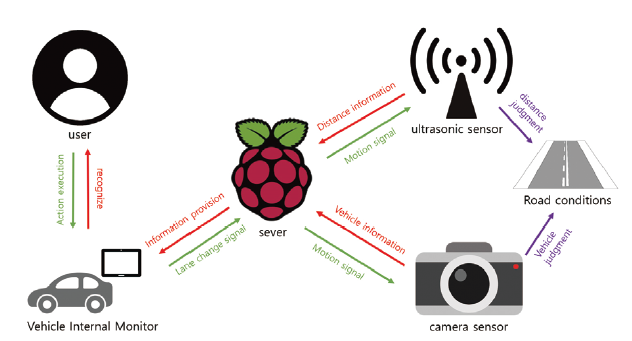
3.2.1. 하드웨어 구성
· Raspberry Pi
· 960-001063 – Webcam, HD Pro, 1280 x 720p Resolution, 3MP, Built In Microphone
· HC-SR04
· Bread Board
· 저항 1K 2개, 저항 2K1개
· Slide switch
· Google Coral USB Accelerator
· MM,MF 타입 점퍼선
3.2.2. 소프트웨어 구성
· OpenCV 영상인식 source
· Ultrasonic sensor source
· Switch On/Off process source
3.2.3. 주요 동작 및 특징
· 영상처리를 통한 뒷 차량 인식
· 초음파센서를 통한 뒷 차량과의 거리 계산
· 스위치를 통한 깜박이 구현
· 영상처리를 통한 차선 변경 안전도 표시
3.2.4. 회로 구성
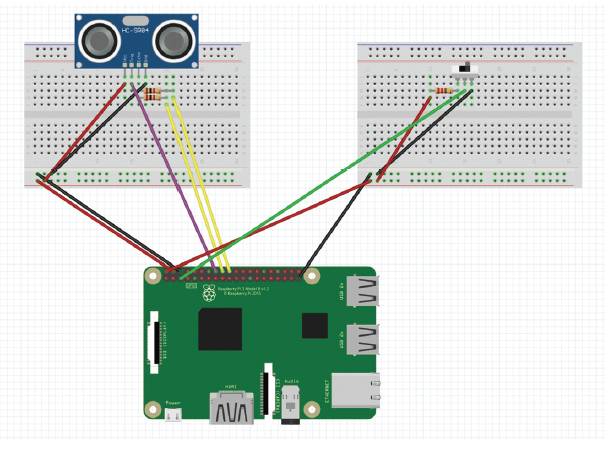
Raspberry Pi 2Pin = Register 1K pin = Switch first pin
Raspberry Pi 4pin = ultrasonic sensor Vcc pin
Raspberry Pi 5pin = Switch second pin
Raspberry Pi 6pin = ultrasonic sensor GND pin
Raspberry Pi 16pin = ultrasonic sensor Trig pin
Raspberry Pi 18pin = Register 2K pin = ultrasonic sensor Echo pin
Raspberry Pi 20pin = Register 1K pin = ultrasonic sensor Echo pin
Raspberry Pi 39pin = Switch third pin
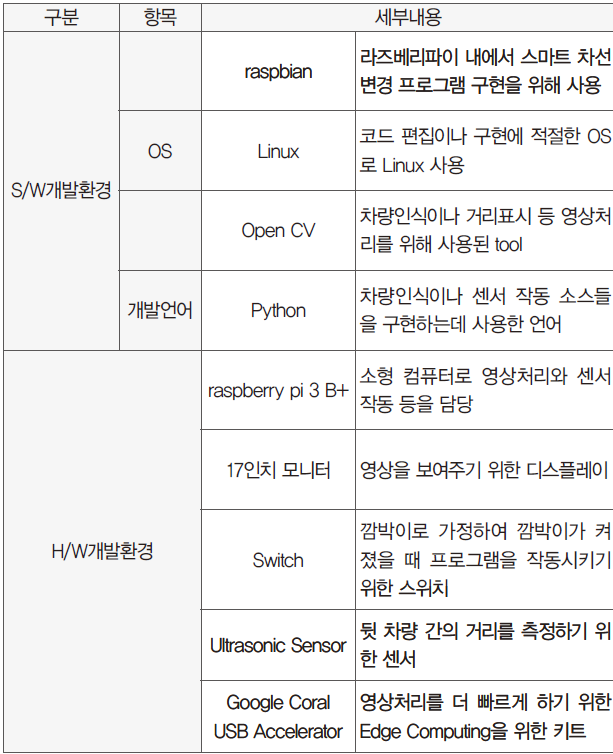
3.3. 개발 환경(개발 언어, Tool, 사용 시스템 등)
4. 단계별 제작 과정
4.1. 라즈베리 파이
4.1.1. 차량인식을 위한 영상처리 구현
구현하고자 하는 프로그램의 핵심은 차량인식이다. 차선 변경 시, 해당 도로에서 운전자 차량을 기준으로 대각선 뒤에 있는 차량과의 거리를 시각적인 정보로 운전자에게 표현하기 위해서는 차량을 인식하는 것이 가장 우선이다. 영상 처리를 위한 환경으로 라즈베리에 tensorflow를 설치하였고 코딩을 위해 Open CV tool도 설치하였다. 언어는 Python을 사용하였다. 여러 가지 환경과 쉘 스크립트를 사용하기 위해 https://github.com/EdjeElectronics/ TensorFlow-Lite-Object-Detection-on-Android-and-Raspberry-Pi.git 저장소를 사용했고, 감지 모델은 tensorflow 홈페이지에서 제공하는 모델을 기반으로 사용했다.

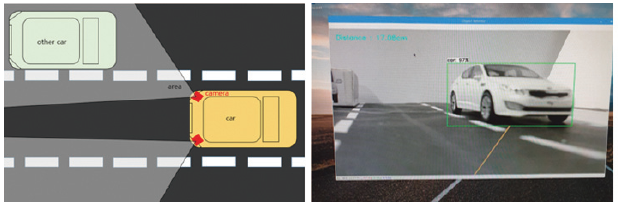
다음은 테스트의 한 부분으로 다음과 같이 차량을 인식하여 차량을 사각형 틀 안에 포함하는 것을 볼 수 있다.

라즈베리 파이 상에서 영상처리를 하였는데 영상 처리가 워낙 많은 연산을 필요로 하다보니 속도가 늦은 단점이 있었다. 이를 개선하기 위해 Google Coral USB Accelerator라는 Edge TPU를 사용하여 속도를 높여주었다.
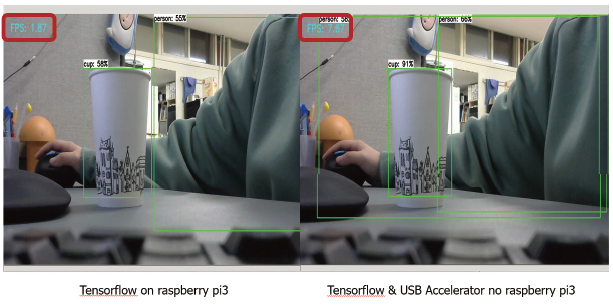
성능을 테스트해보기 위해 FPS를 측정해 보았다. Google Coral USB Accelerator 장착했을 때 FPS가 4배 가까이 증가하는 것을 확인할 수 있었고, 좀 더 빠른 영상처리를 할 수 있었다. 하지만 실시간으로 이용하기에는 조금 부족한 면이 있었지만 이는 라즈베리보다 좀 더 성능이 좋은 소형 컴퓨터를 이용하면 해결될 것이라고 본다. 예들 들면 Nvidia사의 Jetson Nano Board나 Raspberry pi 4 등이다.
4.1.2. 운전자가 쉽게 차량까지의 거리를 인식할 수 있게 시각화하기
운전자 차량을 기준으로 변경하고자 하는 차선의 차량까지의 거리는 cm단위로 초음파 센서를 통해 측정하였으며, 좌측 상단에 “Distance : ”로 출력형태를 갖는다. Python OpenCV를 통해 거리를 선으로 표시하며 색(빨간색, 주황색, 초록색)을 통해 상황에 따라 구별할 수 있도록 한다.
운전자 차량까지의 거리를 인식할 수 있는 구체적인 설명으로는 거리측정을 위한 초음파 센서를 연결하고, 초음파 센서에서 반환값을 받아온다. 여기서 받아온 값은 구하고자 하는 거리가 되며 cm단위(테스트를 모형에서 실시했기 때문에 거리를 cm로 조정)를 갖는다. 여기서 운전자 차량과 변경하고자 하는 차선의 차량과의 거리는 선으로 표시한다. 이 선은 거리에 따라서 색을 다르게 표현하는데, 만약 거리가 16cm이하라면, 해당 선을 빨간색으로 하여 차선변경이 불가능하다고 알려주고, 16cm~ 20cm 사이면 해당 선은 주황색으로 차선 변경 시 주의해야 한다고 알려주며, 20cm이상이면 해당 선은 초록색으로 차선 변경을 하여도 안전하다고 표시하도록 구성하였다.
테스트는 다음과 같이 진행하였다. 카메라는 운전자 차량의 후면에 부착하였다고 가정한 상태에서 빨간색 차량이 운전자의 차량이며 운전자가 좌측 방향 지시등을 켰을 때, 운전자 차량을 기준으로 좌측 도로 상황을 비추게 된다. 카메라는 OpenCV를 통해 차량을 인식하는 동시에 앞서 말한 시각화 과정으로 차선 변경 가능 여부를 선과 색으로 운전자에게 알려준다. 다음의 테스트에서는 라즈베리 파이 모델 3 2015버전을 사용하였고 초음파 센서의 모델명은 HC-SR04, 카메라는 Logitech사의 960-001063 – Webcam, HD Pro, 1280 x 720p Resolution, 3MP, Built In Microphone을 사용하였다. 실제 차량을 사용할 수 없어 차량 모델을 제작하여 테스트를 진행하였다.




회로 사진 및 라즈베리파이 pin 연결

초음파 센서 회로도
4.1.3. 스위치를 이용한 방향 지시등 구현
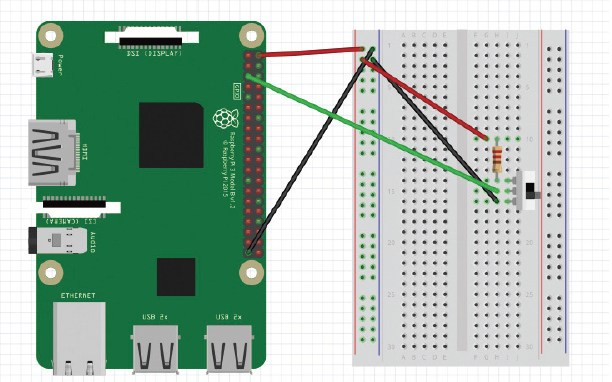
운전자가 방향 지시등을 켰을 때 다음 프로그램이 실행되므로 슬라이드 스위치를 차량의 방향 지시등으로 가정하여 구현하였다. 슬라이드 스위치가 ON일 때, 프로그램을 시작하거나 프로그램이 지속적으로 실행하도록 한다. 슬라이드 스위치가 OFF일 때, 프로그램을 종료하도록 구성하였다. 실험을 진행 할 때, 일반적인 택트 스위치 같은 경우 직접 스위치를 계속해서 누르고 있어야 ON으로 인식을 하는 번거로움을 가져왔다. 따라서 슬라이드 스위치를 이용하여 실제 차량의 방향지시등의 점멸을 표현하였다. 슬라이드 스위치의 작동 실험은 시연 동영상을 통해 볼 수 있다.
회로 사진
회로도
4.1.4. 주요 소스 코드
import RPi.GPIO as GPIO
from time import sleep
import os
import argparse
import cv2
import numpy as np
import sys
import time
from threading import Thread
import importlib.util
import signal
left_switch = 3 #Switch assumed as signal light
#GPIO Setting
GPIO.setmode(GPIO.BCM)
GPIO.setwarnings(False)
GPIO.setup(left_switch,GPIO.IN,GPIO.PUD_UP)
GPIO.setup(right_switch,GPIO.IN,GPIO.PUD_UP)
def distanceInCm(duration): #Function that returns duration as distance in cm
return (duration/2)/29.1
def print_distance(distance): #A function that sets the distanceMsg differently depending on the distance value.
if distance == 0:
distanceMsg = ‘Distance : out of range \r’
else:
distanceMsg = ‘Distance : ‘+str(distance)+’cm’+’ \r’
return distanceMsg
#Set pin number of ultrasonic sensor
TRIG = 23 #TRIG Numbering
ECHO = 24 #ECHO Numbering
MAX_DISTANCE_CM = 300
MAX_DURATION_TIMEOUT = (MAX_DISTANCE_CM * 2 * 29.1)
GPIO.setmode(GPIO.BCM)
GPIO.setup(TRIG, GPIO.OUT) #TRIG Ultrasonic Signal Transmission Pin Designation and Specify Output
GPIO.setup(ECHO, GPIO.IN) #Specify ECHO Ultrasonic Signal Receiving Pin and Specify Output
#Thread to manage webcam
class VideoStream:
“”"Camera object that controls video streaming from the Picamera”"”
def __init__(self, resolution=(640,480), framerate=30):
self.stream = cv2.VideoCapture(0) #Trun on the camera
ret = self.stream.set(cv2.CAP_PROP_FOURCC, cv2.VideoWriter_fourcc(*’MJPG’))
#frame size init
ret = self.stream.set(3, resolution[0])
ret = self.stream.set(4, resolution[1])
# Read first frame from the stream
(self.grabbed, self.frame) = self.stream.read()
# Variable to control when the camera is stopped
self.stopped = False
def start(self): # Start the thread that reads frames from the video stream
Thread(target=self.update,args=()).start()
return self
def update(self): #Keep looping indefinitely until the thread is stopped
while True:
#If the camera is stopped, stop the thread
if self.stopped:
#Close camera resources
self.stream.release()
return
#Otherwise, grab the next frame from the stream
(self.grabbed, self.frame) = self.stream.read()
def read(self): #Return the most recent frame
return self.frame
def stop(self): #Indicate that the camera and thread should be stopped
self.stopped = True
#Define and parse input arguments
parser = argparse.ArgumentParser()
parser.add_argument(‘–modeldir’, help=’Folder the .tflite file is located in’, required=True)
parser.add_argument(‘–edgetpu’, help=’Use Coral Edge TPU Accelerator to speed up detection’, action=’store_true’)
args = parser.parse_args()
MODEL_NAME = args.modeldir
GRAPH_NAME = args.graph
LABELMAP_NAME = args.labels
min_conf_threshold = float(args.threshold)
resW, resH = args.resolution.split(‘x’)
imW, imH = int(resW), int(resH)
use_TPU = args.edgetpu
#Import TensorFlow libraries
#If tensorflow is not installed, import interpreter from tflite_runtime, else import from regular tensorflow
#If using Coral Edge TPU, import the load_delegate library
pkg = importlib.util.find_spec(‘tensorflow’)
if pkg is None:
from tflite_runtime.interpreter import Interpreter
if use_TPU:
from tflite_runtime.interpreter import load_delegate
else:
from tensorflow.lite.python.interpreter import Interpreter
if use_TPU:
from tensorflow.lite.python.interpreter import load_delegate
#If using Edge TPU, assign filename for Edge TPU model
if use_TPU: #If user has specified the name of the .tflite file, use that name, otherwise use default ‘edgetpu.tflite’
if (GRAPH_NAME == ‘detect.tflite’):
GRAPH_NAME = ‘edgetpu.tflite’
#Get path to current working directory
CWD_PATH = os.getcwd()
#Path to .tflite file, which contains the model that is used for object detection
PATH_TO_CKPT = os.path.join(CWD_PATH,MODEL_NAME,GRAPH_NAME)
#Path to label map file
PATH_TO_LABELS = os.path.join(CWD_PATH,MODEL_NAME,LABELMAP_NAME)
#Load the label map
with open(PATH_TO_LABELS, ‘r’) as f:
labels = [line.strip() for line in f.readlines()]
#Have to do a weird fix for label map if using the COCO “starter model” from
#https://www.tensorflow.org/lite/models/object_detection/overview
#First label is ‘???’, which has to be removed.
if labels[0] == ‘???’:
del(labels[0])
#Load the Tensorflow Lite model.
#If using Edge TPU, use special load_delegate argument
if use_TPU:
interpreter = Interpreter(model_path=PATH_TO_CKPT,
experimental_delegates=[load_delegate('libedgetpu.so.1.0')])
print(PATH_TO_CKPT)
else:
interpreter = Interpreter(model_path=PATH_TO_CKPT)
interpreter.allocate_tensors()
#Get model details
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
height = input_details[0]['shape'][1]
width = input_details[0]['shape'][2]
floating_model = (input_details[0]['dtype'] == np.float32)
input_mean = 127.5
input_std = 127.5
#Initialize frame rate calculation
frame_rate_calc = 1
freq = cv2.getTickFrequency()
#Initialize video stream
videostream = VideoStream(resolution=(imW,imH),framerate=30).start()
time.sleep(1)
#for frame1 in camera.capture_continuous(rawCapture, format=”bgr”,use_video_port=True):
while True:
if GPIO.input(left_switch) == 1: #Start timer (for calculating frame rate)
t1 = cv2.getTickCount()
#Grab frame from video stream
frame1 = videostream.read()
#Acquire frame and resize to expected shape [1xHxWx3]
frame = frame1.copy()
frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frame_resized = cv2.resize(frame_rgb, (width, height))
input_data = np.expand_dims(frame_resized, axis=0)
#Normalize pixel values if using a floating model (i.e. if model is non-quantized)
if floating_model:
input_data = (np.float32(input_data) – input_mean) / input_std
#Perform the actual detection by running the model with the image as input
interpreter.set_tensor(input_details[0]['index'],input_data)
interpreter.invoke()
#Retrieve detection results
boxes = interpreter.get_tensor(output_details[0]['index'])[0] #Bounding box coordinates of detected objects
classes = interpreter.get_tensor(output_details[1]['index'])[0] #Class index of detected objects
scores = interpreter.get_tensor(output_details[2]['index'])[0] #Confidence of detected objects
#num = interpreter.get_tensor(output_details[3]['index'])[0] #Total number of detected objects (inaccurate and not needed)
pulse_start=0
pulse_end=0
GPIO.output(TRIG, False) #Keep the trigger pin off.
time.sleep(2)
GPIO.output(TRIG, True) #Exits 10us pulse.
time.sleep(0.00001) #At Python, this pulse will be almost 100 us.
GPIO.output(TRIG, False)
timeout = time.time()
while GPIO.input(ECHO) == 0:
pulse_start = time.time() #Set the start time when the echo pin is turned on.
if ((pulse_start – timeout)*1000000) >= MAX_DURATION_TIMEOUT:
fail = True
break
timeout = time.time()
while GPIO.input(ECHO) == 1:
pulse_end = time.time() #Set the reflector receiving time when the echo pin is turned off.
if ((pulse_end – pulse_start)*1000000) >= MAX_DURATION_TIMEOUT:
print_distance(0)
fail = True
break
pulse_duration = (pulse_end – pulse_start) * 1000000
pulse_duration=pulse_end-pulse_start #Calculate pulse length
distance = distanceInCm(pulse_duration)
distance=(pulse_duration*34000.0)/2 #The duration is divided in half.
distance = round(distance, 2)
MSG=print_distance(distance)
#Loop over all detections and draw detection box if confidence is above minimum threshold
for i in range(len(scores)):
if ((scores[i] > min_conf_threshold) and (scores[i] <= 1.0)):
#Get bounding box coordinates and draw box
#Interpreter can return coordinates that are outside of image dimensions, need to force them to be within image using max() and min()
ymin = int(max(1,(boxes[i][0] * imH)))
xmin = int(max(1,(boxes[i][1] * imW)))
ymax = int(min(imH,(boxes[i][2] * imH)))
xmax = int(min(imW,(boxes[i][3] * imW)))
cv2.rectangle(frame, (xmin, ymin), (xmax, ymax), (10, 255, 0), 2)
a=(xmax-xmin)/2
b = int(a)
if distance < 16:
frame = cv2.line(frame, (650, 720), (xmin+b, ymax), (0, 0, 255), 3)
elif distance >=16 and distance < 20:
frame = cv2.line(frame, (650, 720), (xmin+b, ymax), (0, 150, 255), 3)
else:
frame = cv2.line(frame, (650, 720), (xmin+b, ymax), (0, 255, 0), 3)
#Draw label
object_name = labels[int(classes[i])] #Look up object name from “labels” array using class index
label = ‘%s: %d%%’ % (object_name, int(scores[i]*100)) #Example: ‘person: 72%’
labelSize, baseLine = cv2.getTextSize(label, cv2.FONT_HERSHEY_SIMPLEX, 0.7, 2) #Get font size
label_ymin = max(ymin, labelSize[1] + 10) #Make sure not to draw label too close to top of window
cv2.rectangle(frame, (xmin, label_ymin-labelSize[1]-10), (xmin+labelSize[0], label_ymin+baseLine-10), (255, 255, 255), cv2.FILLED) #Draw white box to put label text in
cv2.putText(frame, label, (xmin, label_ymin-7), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 0), 2) #Draw label text
#Draw distance in corner of frame
cv2.putText(frame, MSG,(30,50),cv2.FONT_HERSHEY_SIMPLEX,1,(255,255,0),2,cv2.LINE_AA)
#All the results have been drawn on the frame, so it’s time to display it.
cv2.imshow(‘Object detector’, frame)
#Calculate framerate
t2 = cv2.getTickCount()
time1 = (t2-t1)/freq
frame_rate_calc= 1/time1
#Press ‘q’ to quit
if cv2.waitKey(1) == ord(‘q’):
break
else: #Exit program if switch off
break
#Clean up
GPIO.cleanup()
cv2.destroyAllWindows()
videostream.stop()
5. 추가할 수 있는 기능
우리는 도로 모형을 제작하여 실험을 진행하였지만 실제 도로 상황에서는 많은 변수가 존재할 수 있다. 우리가 생각한 변수 중의 하나는 바로 ‘속도’이다. 뒷 차량이 어느 정도 속도로 오는지 알 수 없기 때문에 우리는 거리를 통하여 속도를 계산해 운전자의 모니터에 거리 정보를 나타낼 때 변수가 되는 속도를 반영하여 나타내는 것이다. 우리는 실제로 실험을 할 수 없어 이 부분의 구현은 하지 않았지만 우리가 만든 프로그램을 실제 차량에 이용한다면 이 부분도 고려하면 좋을 것 같다. 아니면 초음파를 받아 오는 시간 간격을 좀 더 줄여도 속도라는 변수를 어느 정도 해결할 수 있을 것 같다.
6. 참고문헌
· https://github.com/EdjeElectronics/TensorFlow-Lite-Object-Detection-on-Android-and-Raspberry-Pi/blob/master/Raspberry_Pi_Guide.md
· https://www.tensorflow.org
· https://blog.naver.com/ljy9378/221438192568
· https://www.diymaker.net/111
· https://www.diymaker.net/111
· https://make.e4ds.com/make/learn_guide_view.asp?idx=73
[65호]초음파센서를 이용한 자동문 쓰레기통


2020 ICT 융합 프로젝트 공모전 장려상
초음파센서를 이용한 자동문 쓰레기통
글 | 대구대학교 정원용
1. 심사평
칩센 얼핏 간단해 보이지만 주제와 부합되는 명확한 목표와 결과물을 확인할 수 있습니다. 작품으로서는 충분히 아이디어를 실제로 구현한 상황이지만, 실용성 측면에서 쓰레기통에 전원을 포함한 하드웨어 회로가 장착되어야 하므로 일체형이 아닌 기존 쓰레기통에 적용할 수 있는 별도 구조는 어떨까 하는 생각이 듭니다.
펌테크 작품의 하우징 구성이 상당히 깔끔하고 훌륭하며 설계에 고생이 많았으리라 생각됩니다. 최근 코로나 등으로 위생에 관련된 비접촉식 생활용품에 관심이 많은 시기와도 맞물리는 완성도가 높은 출품작으로 생각됩니다.
위드로봇 전력 관리 부분이 추가되면 더욱 좋은 작품이 될 것 같습니다.
2. 작품 개요
2.1. 배경 및 요약
2.1.1. 더러운 쓰레기통의 위생상 문제
· 쓰레기통 공간이 없어 쓰레기를 쓰레기통 주변에 버려서 쓰레기통이 더러워짐
· 더러운 쓰레기통으로 인해 접촉하기 어려움
· 자동문 쓰레기통을 활용해 접촉을 줄여 위생상의 문제 해결
2.1.2. 쓰레기통 주변 환경 문제
· 쓰레기통의 내용물이 다 찼는지 알지 못해 쓰레기통이 넘치게 됨
· 넘치는 쓰레기통으로 인해 주변이 더러워짐
· 쓰레기통이 다 찼을 시 알림 기능으로 넘치는 쓰레기통 문제 해결
2.1.3. 작품 기능
2.1.3. 완성본

· 평상 시, 초록 LED와 쓰레기통이 닫혀있음
· 물체가 인식될 시, 쓰레기통이 열림
· 쓰레기통이 일정량 채워지면 빨간 LED로 바뀜
3. 작품 설명
3.1. 주요 동작 및 특징
3.1.1. 주요 동작 순서도

3.1.2. 자동문 휴지통 순서도
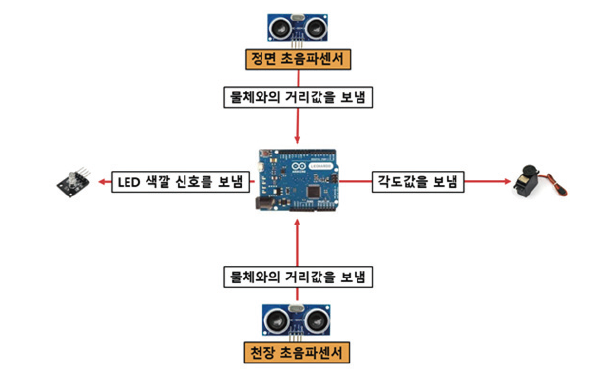
· 초음파센서를 통해 정면에 있는 물체와의 거리를 측정
· 측정된 물체와의 거리에 따라 쓰레기통이 열리고 닫힘
· 쓰레기통 천장에 있는 초음파센서로 쓰레기 인식
· 초음파센서로 쓰레기양에 따라 LED의 색깔이 바뀜
3.1.3. 물체 인식
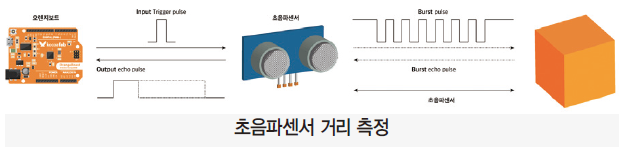
· 가까운 거리의 물체 인식을 위한 초음파센서 사용
· 초음파센서로 가까운 거리의 물체와의 거리 측정
· 초음파센서에서 발사된 초음파가 물체로부터 반사되어 돌아온 시간으로 거리산출
· 산출된 거리가 일정 거리보다 작아지면 물체 인식
3.1.4. 쓰레기통의 자동문

· 쓰레기통의 덮개 부분이 움직이면서 쓰레기통이 열리고 닫히게 됨
· 서보모터를 축으로 덮개 부분이 돌아가도록 설계
· 물체를 인식하여 덮개가 움직이는 자동문
3.1.5. 쓰레기통 알림 기능

· 쓰레기통 알림 기능을 위해 LED를 사용
· 평상시에는 LED에 초록 불이 켜짐
· 쓰레기통이 다 찼을 시에는 LED에 빨간 불이 켜짐
3.2. 전체 시스템 구성
3.2.1. 하드웨어(HW)
아두이노 우노 보드 : 아두이노 가장 보편적이고 기본적인 보드
초음파센서 HC-SR04 : 물체와의 거리 측정을 위해 사용
서보모터 hs-311 : 쓰레기통이 열리고 닫히게 하기위해 사용
RGB 3색 LED : 상태를 LED로 표시해주기 위해 사용
3.2.2. 소프트웨어(SW)
Arduino : 작품의 소프트웨어 설계
3.2.3. 전체 시스템 구성도
3.3. 개발 환경
개발 환경
· OS : windows 10
· 개발 환경(IDE) : Arduino
· 개발 언어 : Arduino
구성 장비
· 디바이스 : 아두이노 우노 보드
· 센서 : 초음파센서(HC-SR04) :
· 사용 장비 : 서보모터 hs-311, RGB 3색 LED
4. 단계별 제작 과정
4.1. Paper Prototype

제작 계획
· 작품 기능 구현
· 외부 프레임 설계
· 3D 프린팅
· 외부 프레임 결합
· 완성품 테스트
· 외부 전원 연결
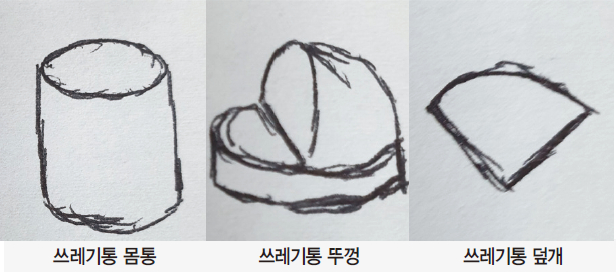
4.2. 외부 프레임 설계
프레임 Paper Prototype
3D Printing

3D 프린터 출력물

외부 프레임 결합
5. 참고문헌
· 한 권으로 끝내는 아두이노 입문 + 실전(종합편)
· https://www.youtube.com/watch?v=h7yyw6p_tZk&t=1s
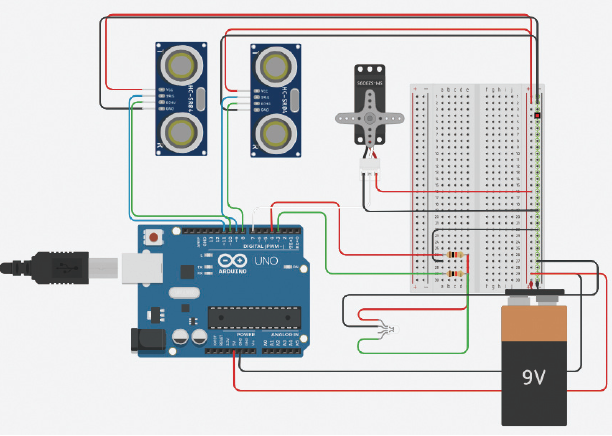
6. 회로도
7. Arduino 소스코드
#include <Servo.h>
Servo servo;
// 각 핀 번호 설정
int value=0;
int echo1 = 8;
int trig1 = 9;
int echo2 = 10;
int trig2 = 11;
int red=4;
int green=3;
// 각 핀의 입출력 설정
void setup() {
Serial.begin(9600);
pinMode(trig1, OUTPUT);
pinMode(echo1, INPUT);
pinMode(trig2, OUTPUT);
pinMode(echo2, INPUT);
pinMode(red,OUTPUT);
pinMode(green,OUTPUT);
servo.attach(7);
}
void loop() {
// 1번 초음파센서에서 초음파 발사 후 초음파가 다시 돌아오는데 걸리는 시간 저장
digitalWrite(trig1, LOW);
digitalWrite(echo1, LOW);
delayMicroseconds(2);
digitalWrite(trig1, HIGH);
delayMicroseconds(10);
digitalWrite(trig1, LOW);
unsigned long duration1 = pulseIn(echo1, HIGH);
// 2번 초음파센서에서 초음파 발사 후 초음파가 다시 돌아오는데 걸리는 시간 저장
digitalWrite(trig2, LOW);
digitalWrite(echo2, LOW);
delayMicroseconds(2);
digitalWrite(trig2, HIGH);
delayMicroseconds(10);
digitalWrite(trig2, LOW);
unsigned long duration2 = pulseIn(echo2, HIGH);
// 초음파를 발산한 후 다시 돌아온 시간을 가지고 거리 측정
float distance1 = ((float)(340 * duration1) / 10000) / 2;
float distance2 = ((float)(340 * duration2) / 10000) / 2;
// 1번 초음파센서로 측정한 거리가 13cm미만일 경우 (쓰레기통에 근접하는 물체가 감지 될 경우)
if(distance1<13) // 쓰레기통의 문을 연다
{
for(;value>=0;value -=2)
{
servo.write(value);
delay(10);
}
delay(3000); // 문이 열린 후 3초의 지연시간을 준다
}else // 아닐 경우
{
for(;value<=100;value +=2) // 쓰레기통의 문이 닫힌다
{
servo.write(value);
delay(10);
}
}
// 2번 초음파센서로 측정한 거리가 9.5cm초과일 경우(쓰레기통 안의 내용물이 다 찼을 경우)
if(distance2<9.5)
{
// LED 빨간불 ON
digitalWrite(green,HIGH);
digitalWrite(red,LOW);
}
else // 아닐 경우
{
// LED 초록불 ON
digitalWrite(green,LOW);
digitalWrite(red,HIGH);
}
// 측정된 거리 값을 시리얼 모니터에 출력
Serial.print(“1 : “);
Serial.print(distance1);
Serial.print(“cm “);
Serial.print(“2 : “);
Serial.print(distance2);
Serial.println(“cm”);
delay(100);
}
[65호]AI-Based Guide Robot System for the Blind


2020 ICT 융합 프로젝트 공모전 장려상
AI-Based Guide Robot System for the Blind
글 | 동양미래대학교 김선우, 김문, 김재아, 최대원
1. 심사평
칩센 개발이 필요한 이유와 사전 정보에 대한 정리가 매우 깔끔하게 되어 있어 목표와 필요한 이유에 대하여 쉽게 이해가 됩니다. AI와 여러 환경에 대응이 가능할 무한궤도 구동 방안 등이 포함되어 있어 작품에 대한 사용자 편의성 또한 충분히 고려된 듯 합니다. 다만 이미 서비스가 제공되고 있는 AI 플래폼과 정형화된 물체(객체)만을 파악하는 형태로는 실생활의 변수를 모두 포함할 수 없다는 점은 고려되어야 할 것으로 보입니다. 이는 차량 ADAS 시스템 또는 무인 자동차 솔루션 조차도 아직도 완벽하지 않은 이유와 동일한 내용으로 볼 수 있습니다. 하드웨어뿐 아니라 소프트웨어 여러 기능 측면에 대한 심도 깊은 연구가 함께 진행되어야 할 것으로 보입니다. 최종 작품이 완성되지 않은 것으로 보여 작품 완성도의 배점 부분이 아쉽습니다.
펌테크 아이디어와 창의성을 갖춘 작품이라고 생각이 듭니다. 단 제출된 보고서 내용을 감안하자면 작품에 대한 기획의도는 우수하다고 생각되지만 계획에 대비해서 출품작의 일부 진행과정은 확인이되나 최종적인 완성도를 구체적으로 확인할 수가 없었습니다
위드로봇 수행한 내용에 비해 보고서 내용이 빈약합니다. 보고서가 좀 더 충실하면 좋은 점수를 받을 수 있었습니다.
2. 작품 개요
2.1. 기술개발 필요성
2.1.1. 사회적 문제
현재 대한민국에서 활동하고 있는 시각장애인 안내견의 수는 약 80마리, 외출할 때 주변 사람이나 보조 기구의 도움이 반드시 필요한 5급 이상의 장애등급을 판정받은 사람은 약 8만 명으로 안내견 수가 턱없이 부족한 편이다. 안내견 한 마리를 교육하고 훈련을 마치는데 필요한 기간은 약 2년, 훈련 기간 소요되는 비용은 약 1억으로 현실적으로 모든 시각장애인들이 안내견을 분양받는 것은 불가능하다. 또한 시각장애인 안내견을 분양받아도 분양 후에는 안내견을 돌보는 비용을 시각장애인 스스로 감당해야 하기 때문에 현실적으로 어려움을 가지고 있다.
2.2. 기술개발 목표와 내용
2.2.1. 기술개발 과제의 추진 목표
현재 대한민국에 주거하는 시각장애인들의 실외, 실내 활동을 하는 데 있어 제한을 최소화하고 삶의 질 향상을 추구하며 사회의 일원으로서 배제되지 않도록 하는 것을 기술개발 과제의 추진 목표로 한다.
2.2.2. 기술개발 내용
SoftWare
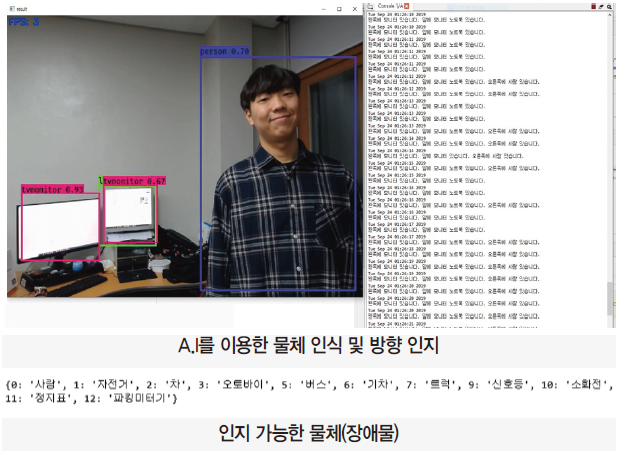
· 카메라를 통해 얻은 영상을 A.I가 내장된 LattePanda Alpha를 통해 약 11가지 객체(장애물) 인지 및 사용자 기준 물체의 방향 알림 역할 수행
· Image Processing, 3축 가속도센서를 사용하여 계단 패턴 분석 및 정확한 계단 및 연석 인지 기능 수행
· 스마트폰 GPS를 이용하여 사용자의 실시간 위치 정보를 Geocoder를 통해 경도와 위도로 변환하여 사용자의 위치를 인지
· 스마트폰에 내장된 GPS의 실시간 위치 정보, Web parsing 기술을 이용한 길 찾기 시스템 구축
HardWare
· Timing Belt Pulley를 이용한 무한궤도 메커니즘 설계를 통한 계단 극복
3. 작품 설명
3.1. 주요 동장 및 특징
3.1.1. S/W
위험 요소 감지 및 음성 안내
· YOLO 알고리즘 기반의 YOLO V3 모델을 구현하여 주변 위험 요소 감지
· 주변 위험 요소 11가지의 위치 파악
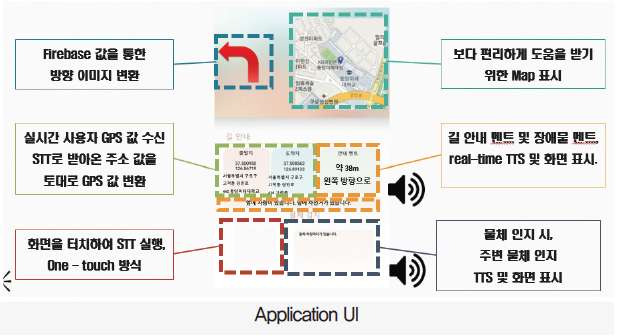
웹파싱을 이용한 길 안내
· 네이버 지도 API를 사용하여 웹파싱 기술을 통해 가공하여 길 찾기 기능 구현
· 현재 GPS 위치 변화에 따른 음성 안내
Android studio Application 제작
· 스마트폰을 통해 사용자의 현재 위치, 길 안내, 장애물 인지 등 사용자에게 필요한 정보 제공
· 주변 사람들의 도움을 보다 편리하게 받을 수 있는 UI
상용 웹서버 Firebase를 활용한 데이터 통신
· 스마트폰에 내장되어 있는 GPS 값의 실시간 데이터를 웹서버에 uploading 하여 실시간 길 찾기 기능 구현
· A.I Device인 LattePanda Alpha를 통해 인지한 객체를 TTS(Text to Speech)를 통해 사용자에게 청각 알림
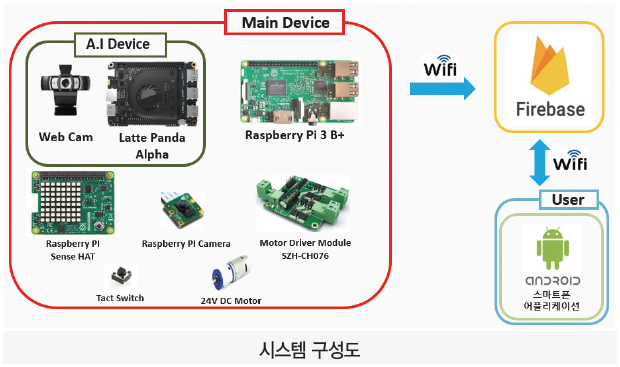
3.1.2. H/W
Main Device
· Raspberry Pi (MCU/MPU), Sensor(3-axis Acceleration, Ultrasonic), Cooling Fan, Speaker(SP-82557S), Timing Belt, Pully, Battery(Lipo 22.2V 5000mAh)
A.I Device
· LattePanda Alpha (MPU), Webcam(Logitech C930e)
3.2. 전체 시스템 구성 및 개발 환경
3.2.1. S/W
A.I
· Webcam을 이용해 촬영 후 LattePanda Alpha에서 연산
· AI YOLO v3 프로그램을 Python으로 구현하여 객체 인식
· LattePanda Alpha가 연산(YOLO v3)결과를 문자열로 재가공 후 Firebase에 결과 출력
Stair Climing
· 3축 가속도센서(3-axis Acceleration) Roll Pitch 값에 따른 로봇의 Motor control
· Image Processing 기반 계단의 pattern 분석 및 정확한 계단 인지

Application Functions
· 사용자 스마트폰에 내장된 GPS기반으로 실시간 사용자 위치(경도, 위도) 수신
· Google STT(Speech to Text)를 사용하여 사용자가 목적지를 음성으로 입력하면 Geocoder를 사용해 위도, 경도로 변환
· Google TTS(Text to Speech)를 사용하여 길 찾기 음성 안내, 장애물 발견 시 위험 요소 음성 안내
· 길 찾기 기능을 수행하기 위한 웹파싱 기능 구현
· ‘다음 맵’API 서비스를 이용하여 스마트폰 디스플레이에 map을 구현

Application UI
· 주변 사람이 한 눈에 보고 도움을 주기 편한 UI로 제작
· 목적지까지의 방향, 실시간 현 위치, 장애물을 디스플레이에 표시하는 심플한 UI
3.2.2. H/W
Harness
· 곡면 modeling을 통해 사용자에게 편안한 그립감을 줄 수 있는 외형 제작

· 3D 프린터(PLA)를 사용해 장시간 들고 있어도 손에 무리가 가지 않도록 무게 최소화
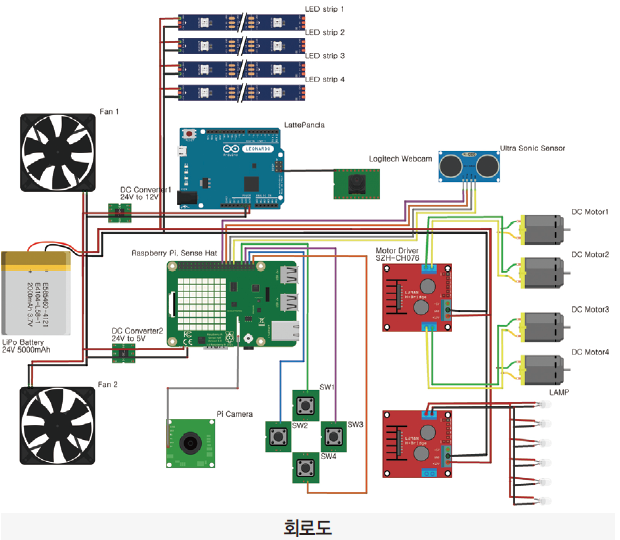
4. 회로도
· 22.2V Lithium Polymer Battery 단일 전원
· Raspberry Pi 3 B+, Latte Panda, SZH-CH076, Fan 총 4개 소자에 공급되며, 각 소자의 정격 전압에 맞게 regulator를 사용
5. 설계도면

6. 소스코드
from sense_hat import SenseHat
import time
import imageprocessing_03 as stair
import MotorController_03 as motor
import cv2
import os
import RPi.GPIO as GPIO
## MOTOR config setting ##
# 모터 상태
STOP = 0
FORWARD = 1
BACKWORD = 2
# 모터 채널
CH1 = 0
CH2 = 1
# PIN 입출력 설정
OUTPUT = 1
INPUT = 0
# PIN 설정
HIGH = 1
LOW = 0
# 실제 핀 정의
#PWM PIN
ENA = 26 #37 pin
ENB = 0 #27 pin
#GPIO PIN
IN1 = 19 #35 pin
IN2 = 13 #33 pin
IN3 = 6 #31 pin
IN4 = 5 #29 pin
SW1 = 17 #13 pin
SW2 = 27 #15 pin
SW3 = 16
SW4 = 20
# 핀 설정 함수
def setPinConfig(EN, INA, INB):
GPIO.setup(EN, GPIO.OUT)
GPIO.setup(INA, GPIO.OUT)
GPIO.setup(INB, GPIO.OUT)
# 100khz 로 PWM 동작 시킴
pwm = GPIO.PWM(EN, 100)
# 우선 PWM 멈춤.
pwm.start(0)
return pwm
# 스위치 핀 함수
def setPinSwitch(SW1, SW2, SW3, SW4) :
GPIO.setwarnings(False)
GPIO.setup(SW1,GPIO.IN,GPIO.PUD_UP)
GPIO.setup(SW2,GPIO.IN,GPIO.PUD_UP)
GPIO.setup(SW3,GPIO.IN,GPIO.PUD_UP)
GPIO.setup(SW4,GPIO.IN,GPIO.PUD_UP)
# 모터 제어 함수
def setMotorContorl(pwm, INA, INB, speed, stat):
#모터 속도 제어 PWM
pwm.ChangeDutyCycle(speed)
if stat == FORWARD:
GPIO.output(INA, HIGH)
GPIO.output(INB, LOW)
#뒤로
elif stat == BACKWORD:
GPIO.output(INA, LOW)
GPIO.output(INB, HIGH)
#정지
elif stat == STOP:
GPIO.output(INA, LOW)
GPIO.output(INB, LOW)
# 모터 제어함수 간단하게 사용하기 위해 한번더 래핑(감쌈)
def setMotor(ch, speed, stat):
if ch == CH1:
#pwmA는 핀 설정 후 pwm 핸들을 리턴 받은 값이다.
setMotorContorl(pwmA, IN1, IN2, speed, stat)
else:
#pwmB는 핀 설정 후 pwm 핸들을 리턴 받은 값이다.
setMotorContorl(pwmB, IN3, IN4, speed, stat)
def RC():
if GPIO.input(SW1) == 0 : #forward
SPEED = 12 #LEFT MOTOR
SPEED1 = 12
setMotor(CH1, SPEED, FORWARD)
setMotor(CH2, SPEED1, BACKWORD)
print(“forward”)
elif GPIO.input(SW2) == 0 : #back
SPEED = 12 #LEFT MOTOR
SPEED1 = 12
setMotor(CH1, SPEED, BACKWORD)
setMotor(CH2, SPEED1, FORWARD)
print(“back”)
elif GPIO.input(SW3) == 0 : #LEFT
SPEED = 1 #LEFT MOTOR
SPEED1 = 15
setMotor(CH1, SPEED, FORWARD)
setMotor(CH2, SPEED1, BACKWORD)
print(“here”)
print(“left”)
elif GPIO.input(SW4) == 0 : #right
SPEED = 15 #LEFT MOTOR
SPEED1 = 1
setMotor(CH1, SPEED, FORWARD)
setMotor(CH2, SPEED1, BACKWORD)
print(“right”)
else :
setMotor(CH1, 0, STOP)
setMotor(CH2, 0, STOP)
print(“stop”)
###########################
def stair_detection():
while True:
print(‘in rc’)
RC() #..
i = 0
while i < 50 :
sense.get_orientation_degrees()['pitch']
i = i + 1
if stair_threshold <= sense.get_orientation_degrees()['pitch']:
print(“up stair”)
setMotor(CH1, 0, STOP)
setMotor(CH2, 0, STOP)
os.system(“sudo service uv4l_raspicam restart”)
os.system(“sudo dd if=/dev/video0 of=image.png bs=11M count=1″)
return stair.stair_detection()
elif sense.get_orientation_degrees()['pitch'] <= -stair_threshold :
print(“down stair”)
setMotor(CH1, 0, STOP)
setMotor(CH2, 0, STOP)
os.system(“sudo service uv4l_raspicam restart”)
# down stair sound
return ‘down’
if __name__ == “__main__” :
os.system(“sudo service uv4l_raspicam restart”)
sense = SenseHat()
stair_threshold = 15 # …
roll_threshold = 10 #
# GPIO 모드 설정
GPIO.setmode(GPIO.BCM)
#모터 핀 설정
#핀 설정후 PWM 핸들 얻어옴
pwmA = setPinConfig(ENA, IN1, IN2)
pwmB = setPinConfig(ENB, IN3, IN4)
setPinSwitch(SW1, SW2, SW3, SW4)
SPEED = 12
SPEED1 = 12
while True:
print(” ##### program start ##### “)
detection = stair_detection()
if detection == True: #up stair
print(‘up stair’)
#up stair sound mp3
while sense.get_orientation_degrees()['pitch'] > 3 :
if sense.get_orientation_degrees()['roll'] > roll_threshold:
setMotor(CH1, 10, FORWARD)
setMotor(CH2, 0, STOP)
print(‘left move’)
elif sense.get_orientation_degrees()['roll'] < -roll_threshold:
setMotor(CH1, 0, STOP)
setMotor(CH2, 10, BACKWORD)
print(‘rigth move’)
elif -roll_threshold < sense.get_orientation_degrees()['roll'] < roll_threshold:
setMotor(CH1, 13, FORWARD)
setMotor(CH2, 13, BACKWORD)
print(‘straight’)
elif detection == ‘down’ :
print(‘down stair’)
while sense.get_orientation_degrees()['pitch'] < -3 :
if sense.get_orientation_degrees()['roll'] > roll_threshold:
setMotor(CH1, 0, STOP)
setMotor(CH2, 13, BACKWORD)
print(‘right move’)
elif sense.get_orientation_degrees()['roll'] < -roll_threshold:
setMotor(CH1, 13, FORWARD)
setMotor(CH2, 0, STOP)
print(‘left move’)
elif -roll_threshold < sense.get_orientation_degrees()['roll'] < roll_threshold:
setMotor(CH1, 10, FORWARD)
setMotor(CH2, 10, BACKWORD)
print(‘straight’)
elif detection == False : #wall or 1 stair
print(“wall”)
setMotor(CH1, 0, STOP)
setMotor(CH2, 0, STOP)
GPIO.cleanup()
6. 완성이미지


7. 참고문헌
· 김윤구 김진욱 논문「도심지형 최적주행을 위한 휠·무한궤도 하이브리드형 모바일 로봇 플랫폼 및 메커니즘」, 로봇학회 논문지 제5권 제3호, 2010
· 박동일 임성균 곽윤근 논문「계단등반을 위한 가변형 단일 트랙 메커니즘 해석」, 대한기계학회 춘추학술대회, 2005.5
· 김의중 저「인공지능, 머신러닝, 딥러닝 입문」, 위키북스, 2016
· 알 스웨이가트 저, 트랜지스터팩토리 역「파이썬프로그래밍으로 지루한 작업 자동화하기」, 스포트라잇북, 2013
· Sam Abrahams Danijar Hafner Erik Erwitt Ariel Scarpinelli 공저, 정기철 역「엣지있게 설명한 텐서플로우」홍콩과학출판사, 2017
· 아담 스트라우드 저, 오세봉 김기환 역 「안드로이드 데이터베이스」, 에이콘, 2017
· http://kpat.kipris.or.kr/kpat/biblioa.do?method=biblioFrame (특허청에 등재된 유사 기술 검색)
[65호]2021 국제인공지능대전


AI and Digital Transformation
2021 국제인공지능대전
글 | 박진아 기자 jin@ntrex.co.kr
(사)한국인공지능협회, ㈜서울메쎄, 인공지능신문이 주최, 주관한 2021 국제인공지능대전이 지난 2021년 3월 24일부터 26일까지 3일간 코엑스에서 진행됐다.
이번 국제인공지능대전은 네이버클라우드, 한국마이크로소프트, 메가존클라우드, 에이모, 크라우드웍스, 인피닉 등 AI 전문기업 150여개사와 기관의 참가해 215부스 규모로 인공지능의 최신 기술과 플랫폼·솔루션, 인공지능 기반 비즈니스 모델, 인공지능 적용 및 도입 전략 등 4차 산업혁명 시대를 혁신으로 이끌 인공지능에 대한 모든 것을 한눈에 확인할 수 있다.
인공지능 전시 외에도 인공지능 전문가들이 참여하는 전문 세미나, 컨퍼런스 등 다양한 행사도 함께 진행되었으며, 정부가 AI 학습을 위한 데이터 구축 사업에만 올해도 수천억원 규모를 투자함에 따라 데이터 가공 서비스와 데이터 라벨링 자동화 플랫폼을 선보인 기업들을 가장 많이 볼 수 있었다.

전시장에 입장하면 가장 먼저 좌측 네이버 클라우드 플랫폼 부스와 우측 에이모 부스를 확인할 수 있었다. 기자는 먼저 익숙한 네이버 클라우드 플랫폼 부스를 방문해 보았다. 해당 부스는 오후 2시가 안 된 시간이었는데도 불구하고 부스에서 나눠주는 팸플릿이나 관련 자료집이 다 동이 난 상태였다. 부스에 전시된 정보를 보면 다양한 문서 형식부터 손글씨까지 정확하게 인식하는 OCR 서비스와 Ai Call 서비스를 확인할 수 있었는데 여기서 OCR이란 사람이 쓰거나 기계로 인쇄한 문자의 영상을 이미지 스캐너로 획득하여 기계가 읽을 수 있는 문자로 변환하는 것을 말한다. 사업자등록증을 온라인으로 첨부할 경우 기존에는 담당자가 수기로 정보를 확인하고 처리하여 시간이 많이 소요되었다면 이 기술을 활용하면 글자 위치를 찾고 어떤 글자인지 자동으로 알아낼 수 있다. 네이버의 Clova AI 기술을 활용하여 주요 비즈니스 활용에 최적화된 고성능 OCR 인식 모델이 적용되었고 한국어, 영어, 일본어, 활자체 및 필기체도 인식이 가능하며 등록된 템플릿의 유사도를 통해 자동 분류가 가능하다. Ai Call은 인공지능 기술 및 음성을 활용하여 사람과 자연스럽게 통화가 가능한 대화형 AI 서비스로 전화를 통한 24시간 문의 응대 및 예약등이 가능하다고 한다. 이런 서비스 뿐만아니라 네이버 클라우드 플랫폼 자체가 갖는 데이터 수집, 저장, 다루는 기능자체도 4차 산업혁명 기술 및 AI, 빅데이터 기술에서 빠질 수 없는 요소이기 때문에 앞으로 클라우드 기술의 발전과 활용이 기대된다.

데이터 대표 기업인 에이모에서는 머신러닝과 인공지능 개발을 돕는 데이터 플랫폼을 선보이며 ‘에이모 엔터프라이즈’ 플랫폼에 AI 라벨링 자동화 기능을 추가해 데이터 라벨러들의 학습 데이터 가공 편의성을 높인 업그레이드 버전을 체험하는 기회를 제공했다.
인공지능을 사용하기 위해서는 다양한 데이터를 주입해야 하는데 AI는 사람이 사용하는 문서, 사진 등을 학습없이 식별할 수 없다. 데이터 라벨링은 인공지능 알고리즘 고도화를 위해 AI가 스스로 학습할 수 있는 형태로 데이터를 가공하는 작업을 말하며 문서, 사진, 동영상에 등장하는 모든 것에 라벨을 달아 AI에 주입하면 AI는 이를 바탕으로 데이터들을 학습하면서 유사한 이미지를 인식할 수 있다고 한다.
에이모 엔터프라이즈는 별도 프로그램 설치나 개발자 도움 없이도 준비된 툴을 누구나 이용할 수 있는 직관적인 UI를 제공하여 사용자가 쉽게 레이블링 작업을 설계할 수 있다. AI 학습 데이터 라벨링이 필요한 기업, 기관, 개인이 데이터 라벨링 프로젝트 설계, 작업자 초대, 학습 데이터 라벨링, 산출 관리 모두 직접 가능하며 2D, 3D, Video와 같이 다양한 유형의 데이터에 알맞은 툴로 정확하고 편리하게 작업할 수 있다.
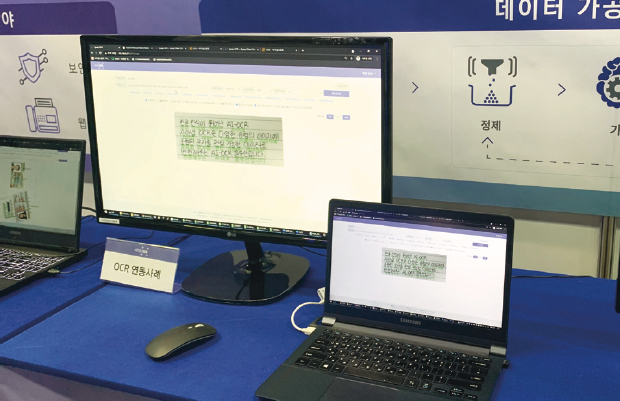

인공지능, 전자문서 전문기업 사이냅소프트에서는 여러대의 컴퓨터를 두고 데이터 레이블링을 시연하고 있었다. 사이냅소프트는 국내 전자문서 시장점유율 1위 기업으로 전자문서 처리 노하우와 기술력을 바탕으로 자체 인공지능 기술을 확보해나가고 있으며, 데이터 레이블링은 인공지능 사업 분야에서 가장주목 받고 있는 기술 중 하나로 이미지, 비디오, 음성, 텍스트 등 다양한 유형의 데이터를 수집 및 가공하고 검수하는 서비스를 제공한다.
당일 레이블캠프와 사이냅 OCR의 성능을 체험하며 설명도 함께 들을 수 있었는데 사이냅 OCR은 AI 딥러닝 기반 문자인식으로 높은 인식률과 빠른 인식 속도와 자체 렌더링 기술로 다량의 학습 데이터를 확보하고 있어 미학습글꼴, 왜곡, 노이즈 등 인식 방해에 강한 특징을 갖고 있다.
한글, 영문, 숫자, 특수 기호를 인식하며 아직은 손글씨 인식은 조금 어렵다고 하나, 현장에서 뚜렷하게 작성된 손글씨는 데이터화 하는 모습도 살펴볼 수 있었다.
레이블 캠프는 크라우드소싱 방식으로 대량의 고품질 데이터를 빠르게 수집 및 가공하는 플랫폼으로 바운딩 박스 등 다양한 어노테이션 도구를 활용한 이미지 라벨링 작업은 물론이고, 물체를 자동으로 가공해 주는 오토 레이블링 기술이 탑재되어 있다. 두번째 이미지 화면에서 빨간색으로 표시되는 부분은 인식하지 못한 부분이라고 하며, 오토 레이블링을 이용해서 작업자는 잘못된 위치만 수정하면 되기 때문에 작업자의 데이터 가공, 작업시간을 현저히 줄여줄 수 있을 것으로 보였다. 이처럼 가독성 높은 시연화면과 상세한 설명으로 해당 부스에는 관람객들의 발길이 끊이지 않았다.

관람객들이 가상현실과 연결되는 장치 착용하고 흥미롭게 체험을 즐기고 있던 부스로는 XR LIFE TWIN인 XR 플랫폼을 선보인 프론티스를 확인할 수 있었다. 프론티스는 AIOT, 5G, AI, VR, MR 기술 기반 맞춤형 솔루션을 개발하는 전문 기업으로 ICT 융복합기술연구소는 4차 산업혁명의 선두주자로 가상증강현실기술과 인공지능의 융복합, 컴퓨터비전, 실감기술, 위치기반 솔루션의 심층연구를 수행하고 있다.
XR 플랫폼으로는 XR 판도라, XR 라이프트윈, XR 워크트윈이 있으며, 사용자의 신체정보 및 햅틱 장비를 통해 높은 몰입감과 현실감을 제공하여 교육 효과를 극대화할 수 있으며, 다수의 사용자가 시간과 장소에 구애받지 않는 장점이 있다. 또한, 높은 접근성, 원거리에 작업자 간 음성 대화 및 영상 공유 기능을 제공하여 시/공간적 제약을 해소해 빠른 업무처리가 가능한 특징이 있는 플랫폼이다.
관람객은 이중 XR 라이프트윈으로 나를 대신하는 아바타가 내 삶을 공유하는 또 다른 세상을 보여주는 메타버스 세컨드 라이프 클라우드 플랫폼을 체험하고 있었다. 라이프트윈을 통하면 비대면으로 강의를 수강할 수도 있고, 직접 강의를 준비하고 진행할 수도 있다고 한다. 하나의 메타버스 시티 당 다수의 아바타가 동시접속이 가능한 클라우드 플랫폼으로 블록체인 디지털 화폐 금융서비스를 도입하여 아바타간 거래 가능한 모든 가상의 동산, 부동산 자산가치를 부여한다. 해당 플랫폼을 이용하여 학교, 일반인 모임, 메타버스 영환관, 박물관등의 비즈니스를 운영할 수 있고, 다양한 VR 콘텐츠 체험, VR 마켓 플레이스로 이용될 수 있다고 한다.

증강현실 관련한 부스로는 마이크로소프트(Microsoft)사의 홀로렌즈2(Hololens 2)를 확인할 수 있었다. 증강현실 디바이스를 착용하면 사람이 작업할 때 Human error를 줄이기 위해 무슨 작업을 해야 하는지 홀로 렌즈가 알려준다.
증강현실이란 실세계에 3차원 가상물체를 겹쳐 보여주는 기술로 한 때 유행했던 포켓몬 Go를 생각하면 이해가 쉬울 것이다. 현장에서 체험할 수 있었던 홀로렌즈 2는 산업용 버전으로 셋팅되어 있었고, 일반용 버전도 있다고 한다. 홀로렌즈 2는 다이얼 인 핏 시스템으로 설계되어 장시간 착용 시에도 편안한 착용감을 제공하고, 바이저를 위로 올리면 손쉽게 혼합 현실에서 빠져나올 수 있다.

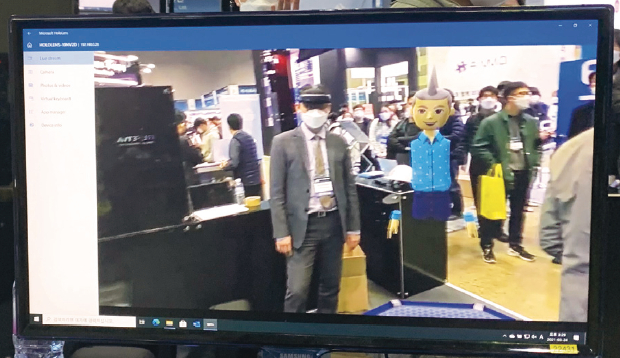
시야각을 넓혀 더 많은 홀로그램을 한 번에 볼 수 있으며 업계 최고의 해상도로 텍스트를 읽고 3D 이미지의 복잡한 세부 사항을 보다 쉽게 확인할 수 있다. 그중에서도 가장 큰 편리함은 전선이나 외부 부속물이 없는 디바이스로 움직임을 방해하지 않는 것과 홀로그램을 자연스럽게 터치하고 만지고 움직일 수 있는게 아닐까 한다.

주식회사 증강지능에서는 스마트 팩토리를 위한 증강현실 플랫폼을 선보였다. 인공지능, 증강현실 기술과 관련된 제품 및 솔루션을 개발하는 증강지능은 인하대학교 인공지능연구실에서 창업한 기업이다.
IAR-MAP은 인공지능과 증강현실이 융합된 플랫폼으로서 작업 상황에 대한 기술 정보들을 각 작업자의 시야 내에서 실시간으로 증강시켜주는 산업용 증강현실 솔루션이라고 한다. 매뉴얼의 그림과 실제 부품을 하나씩 비교해 볼 필요가 없으며, 복잡한 매뉴얼을 살펴보며 고민하지 않아도 되는 장점이 있다고 한다.
IAR-MAP의 주요 기능을 살펴보면 클라우드의 레거시 정보와 연결된 AR 콘텐츠로 한 서버에서 각 작업자들에게 작업지시문서를 할당할 수 있고, Knowledge Manager와 Contents Creator는 레거시 기술문서를 지식으로 변환하고, AR콘텐츠를 효율적으로 빠르게 제작할 수 있도록 도와준다. 또한, 실감형 기술자 훈련 및 교육, AR 기반 원격 정비 등 이 가능하다고 한다. 해당 제품은 스마트 팩토리 및 항공기, 국방, 자동차, 조선, 의료 및 교육 등 다양한 산업분야에서 활용이 가능해 보였다.

비전문가 대상의 딥러닝 비전 소프트웨어 기업 뉴로클(NEUROCLE)에서는 뉴로티(Neuro-T)와 뉴로알(Neuro-R)을 선보였다. 뉴로티는 이미지 해석용 딥러닝 모델을 생성할 수 있는 범용 소프트웨어로 사용자가 GUI상에서 이미지 데이터를 자유롭게 관리할 수 있으며 자체 Auto Deep Learning 알고리즘을 활용하여 코딩없이도 최적의 모델을 생성한다. 뉴로알은 뉴로티에서 생성된 모델을 현장에 적용할 수 있는 런타임 API로 대규모 서버 PC부터 임베디드 프로세서까지 다양한 플랫폼을 지원하면 각 플랫폼에 최적화된 인퍼런스를 제공한다.
Auto Deep Learning을 통해 재학습 과정이 불필요하며 외부 이해관계자의 개입이 없어 빠른 기술 도입이 가능한 점이 특징이다. 또한, 학습한 딥러닝 모델을 활용하여 새로운 Data에 대해 이미지 자동 판독이 가능하여, 의료 이미지 해석, 제품 표면 검사, 얼굴 인식, 자동차 번호판, 제조업의 양품·불량품 검사에 활용할 수 있다고 한다. 전시장에서는 딥러닝을 통해 제품의 파손영역을 인식하는 모습을 확인할 수 있었다.
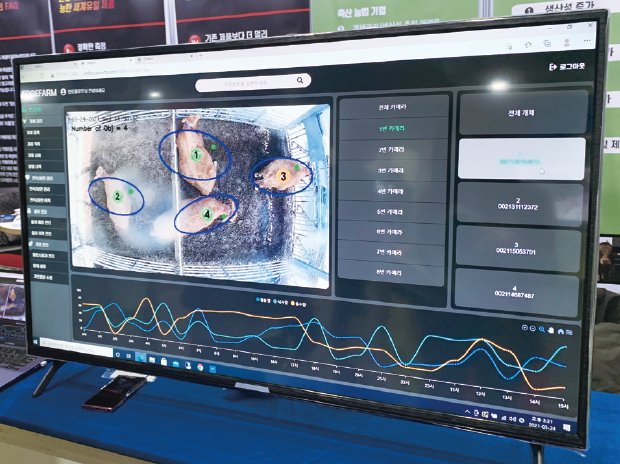
딥러닝 기술을 활용하여 축산 분야의 개체 관리를 효율적으로 바꾼 기업도 볼 수 있었다. 인트플로우 주식회사의 비접촉 축산개체관리 솔루션 엣지팜 카우는 체내에 삽입하거나 부착하는 물리적 방법이 아닌 오로지 영상 분석 기술로만 실현하는 개체관리 시스템으로 엣지팜 카우 메니저, 고정형 CCTV(8채널)로 소의 이상행동을 감지하고 실시간으로 전송한다.
기존 농가에서는 송아지 폐사율을 낮추기 위해 한 마리 한 마리 일일이 직접 소의 건강 상태를 체크하며 24시간 축사에 상주해야 했지만, 엣지팜 카우를 사용하면 AI가 실시간으로 돼지의 식사 횟수부터 활동량, 이상행동 빈도, 질병 여부 확인까지 꼼꼼하게 관리할 수 있다고 한다.
번식부터 출하까지 모든 이력을 통합된 빅데이터 플랫폼에서 관리하며 컴퓨터와 스마트폰으로 어디서든 이용할 수 있으나 월정액을 납부해야한다. 소의 분만, 발정 등 중요한 일도 카카오톡 알림+영상 클립을 통해 바로 확인할 수 있어 효율적인 개체관리가 가능해 보인다.


후원사인 한국전자통신연구원(ETRI)부스에서는 AI 범죄·치안 관련 기술인 치안 민원응대 폴봇 기술, 인공지능 얼굴정보 인식 기술, 지능형 범죄 위험도 예측기술을 선보였다.
폴봇 기술은 치안 분야 전화민원 상의 음성을 인식하고 대화 의도를 파악함으로써 치안 지식을 활용한 양방향 음성 대화 기반 치안 민원 자동응대 기술이다. 전화콜 음성데이터를 전사 및 전처리한 후 음성 모델 및 언어모델을 기반으로 음성 내용을 분석한다. 폴봇이 대화의 의도를 추론하고 기존 구축한 데이터베이스에서 의도에 맞는 응답의 텍스트 내용을 발화자 음성으로 합성해 전달한다. 폴봇 기술은 단순민원업무 전화상담 서비스, 실버세대 말동무 대화 서비스, 대화형 지역관광안내 서비스, 음성인식 대화형 학습도우미 분야에 적용될 것이며 상담인원은 고객 응대에 더욱 집중하여 민원응대 서비스 향상이 가능하다고 한다. 지능형 범죄 위험도 예측기술은 국민들의 치안 안전을 위해 각종 치안 정보를 통합·분석해 경찰에 신고된 사건의 유형과 위험 수준을 초기 인지하고 주변 인물 관계, 범죄 발생 주요 요인을 분석해 의사결정을 지원한다.
얼굴정보 인식 기술은 사람의 얼굴에서 나타나는 정보를 통합적으로 인식해 로봇이 사회적 상호작용 단서를 이해하고 적절히 반응함으로써 사람과 로봇 간의 자연스러운 상호작용을 가능하게 하는 기술이다.
Vision AI 기반 탐지, 추적, 식별, 검색 솔루션을 제공하는 넥스리얼(NEXREAL)에서는 인공지능 센서카메라와 AI기반 영상객체 탐지, 추적, 기술 솔루션을 전시했다. 솔루션은 자체 비전 AI 플랫폼을 내장한 카메라(AI@Camera) 및 게이트웨이(AI@Edge) 장비와 서버용 프로그램 S/W(AI @Server)로 구성된 3-Tier 분산·통합 시각인공지능(Vision AI) 솔루션을 의미한다.

이미지 하단에 보이는 사각형의 제품들은 AI 카메라와 AI 게이트웨이로 AI 카메라는 넥스리얼이 자체 설계 제작한 임베디드 Vision AI 플랫폼 모듈이 내장된 지능형 센서 카메라로 RGB 센서, Depth 센서(스테레오, 3D ToF), Thermal 센서(LWIR)와 선택적 결합해 2D AI 카메라, 3D AI 카메라, 열화상 AI 카메라 또는 멀티모달(RGB-Depth-Thermal) AI 카메라 형태로 제공된다. AI 게이트웨이는 RTSP 또는 HDMI 비디오 스트림을 수신하여 AI 기반 객체 탐지·추적·식별 등 영상분석을 수행하고, 영상분석 메타 데이터를 원본 비디오와 함께 RTSP로 재전송하는 변환장치라고 한다.
이러한 솔루션은 객체 탐지 추적, 이상행동 감지, 공항 자동출입국 심사대, 해안 경비 시스템 등 다양한 분야에서 활용된다고 한다.
이밖에도 AI 화상솔루션, 교육 솔루션, 비대면 입출입 기기 및 장비, 키오스크, 감지 및 식별 시스템, 금융, 유통 물류 등의 각종 솔루션과 기기를 참관하고 직접 시연할 수 있었다. 챗봇 및 어시트턴트, RPA, 5G·네트워크, IoT, 자율주행, 의료·헬스케어, 금융, 보안, 제조·유통·소매, AI로봇 등을 직접 체험하고 관련 인사이트를 공유하였다.
이번 국제인공지능대전은 8개국 138개사, 23,263명이 참관했으며 다양한 전시회들이 코로나로 인해 연기되었음에도 불구하고, 정해진 일정에 맞게 정상 개최된 국제인공지능대전 AI EXPO에는 첫날부터 많은 관람객이 인산인해를 이루는 모습을 볼 수 있었다. 코로나로 인해 입장 인원에 대한 제한이 있었기에 일부가 들어갔다 나오면 들어갈 수 있어 어쩔 수 없는 기다림의 시간도 있었지만, 인공지능, ICT, IoT 산업의 전체적인 동향과 발전된 기술을 한번에 확인할 수 있는 뜻깊은 전시회였다.
2020년 10월 개최했던 국제인공지능대전보다 규모도 크고, 개인적으로 볼거리나 얻을 수 있는 정보가 더 많았던 2021년 국제인공지능대전으로 생각된다. 내년에는 또 어떤 기술의 발전으로 관람객들을 놀라게 할지 기대해보며 이번 관람기를 마친다. DM
[64호] 로봇 & 드론용 초소형 초음파 센서 모듈 STMA-807H


센서텍
로봇 & 드론용 초소형 초음파 센서 모듈 STMA-807H
차량, 로봇, 주차 유도 센서 등 다양한 고기능 센서를 개발 및 연구하는 ‘센서텍’은 I2C 통신 방식의 로봇 & 드론용 송수신 일체형 초음파 센서 ‘STMA-807H’를 출시했다 STMA-807H는 거리 측정과 사람 및 물체를 감지하며 로봇 및 드론용 초음파 센서 모듈로 사용할 수 있으며, 매 100ms마다 지속 적인 거리 센싱이 가능하다. 또한 22mm x19.9mm x 15.2mm 크기로 매우 작으며, 회로에 쉽게 장착이 가능하여 다른 사이즈가 큰 모듈보다 사용하는데 훨씬 편하고 범용성이 좋다. I2C Slave 모드 및 클록 속도 100KHz 로 설정하여 사용해야 하고 작은 사이즈만큼 전력 소모도 매우 낮으며, -20℃에서 최고 60℃까지 사용이 가능하여 어디서든 사용이 가능한 넓은 온도 범위를 가지고 있다. STMA-807H를 사용할 때는 고전류, 고전 압 기타 강렬한 전자파 노이즈의 발생이 우려 되는 장소를 최대한 피해주며 모듈의 앞부분인 센서 쪽에 충격을 가하거나 압력을 가하면 제품이 손상될 우려가 있으니 조심해야 한 다. 전용 어셈블리 케이블 또한 디바이스마트에 판매 중이며, 자세한 제품 사용 설명은 제품 페이지의 첨부 자료를 참고하면 편리하다.